
What is BC? How can we use it?

By Surya Vengadesan
Introduction
In this blog post, we will be covering imitation learning, reinforcement learning’s sibling. While the goal of reinforcement learning is to cleverly solve a policy given an MDP that models an environment (see prev. post), the goal of Imitation Learning is to learn a policy given just trajectories of an agent within the MDP. In particular, we will be covering a specific algorithm called Behavioral Cloning (BC), which was employed to train self-driving vehicles all the way back in the 1980’s, and was used in the first implementation of Alpha-Go. If you are unfamiliar with RL and MDP’s, don’t worry, that information can be abstracted away for understanding the ideas below.
Behavioral Cloning
The main idea behind Behavioral Cloning is to learn a policy for an MDP given expert demonstrations. For example, you might collect a dataset of someone’s steering directions given an image from a car to learn a policy that can do rudimentary self driving. This policy is simply a function that maps a set of states to a distribution over actions. The natural question to ask is, how does one construct such an algorithm? In this blog post, we will cover the required theory, then proceed to layout the building blocks of a BC algorithm and implement it inside an OpenAI gym environment.

In order to best fit a policy with demonstrations, we first need to introduce the concept of likelihood. In short, for those familiar with statistical inference, BC performs maximum likelihood estimation. We want to estimate the parameters of a model that best fits to demonstrations, by assigning high likelihoods to the demonstrations under the learned policy.
MLE on Buffon’s Needle
What does it mean to maximize likelihood? While a probability maps some event to a chance of it occurring, a likelihood maps a model parameter to the joint probability of a set of observations. To solidify this defintion, let’s perform maximum likelihood estimation on a common probability problem — Buffon’s Needle.

Given a set of parallel lines equally separated by distance d, you randomly drop the needle of length lll between the lines, what’s the probability that the needle touches the lines. The parameters here are {l,d}, which we can attempt to estimate given some sample droppings. Formally, if we define x to be the distance from the midpoint of a needle to the closest line, and θ to to be the angle of intersection as defined above, we get the nice uniform probability distributiondefined by Buffon, a French naturalist.
Assume we fix the distance between two parallel lines to d=3, and assume we are given trial datapoints of a needle dropped three times, each time touching a line:
What length l parameter will maxmize the likelihood of recreating this dataset? Given that likelihood is defined as the product of the probabilites of the observations occuring we have the following form:
To solve for this specific example, we can first find the boundaries of the parameter and choose one that maximizes the likelihood function above. The first boundary is that l<d so a needle cannot intersect more than one line at a time. Also, by the geometry of the problem, the needle intersects when
which gives us three additional inequalities.
The intersection of all these intervals is
Now,
We have just shown, that given some observations, we can compute the length of the needle (i.e. l=3) that most likely produced the data. This set of analytic steps to find optimal paramters, is in essence what we do with BC, but on more complex environments where nice steps can no longer be applied.
MLE for Policy Estimation
Therefore, when applying this technique to the setting of reinforcement learning and control, we can represent an event as a trajectory (i.e. a set of sequential state action pairs) which has a specific probability of occurring given a policy. Below, τ is the trajectory of state action pairs (si,ai), π(ai∣si) is the policy’s proability of taking an action ai given you are in state si, and T(⋅) is the transition proability of ending up in state si+1 given you took the state action pair (si,ai):
Given a dataset of such demonstration trajectories, the likelihood therefore would be the product of all the probabilities of the individual trajectories. The below equation should resemble the example above with Buffon’s needle:
In order to estimate the parameters for more complex models, we can use supervised learning techniques, such that given a set of input states and output actions, we learn a mapping between the two that serves as the policy. By tuning the parameters of a supervised learning model, we can solve the MLE problem above.
Therefore, the first step in solving this optimization problem is to pick a specific model to optimize. For example, the model could be some neural network that takes a state as input and outputs an action. The specific neural network architecture you use should be chosen and engineered for your specific task.
BC on Cartpole
In the remainder of this article, we will put all of these pieces together as we construct a behavioral cloning implementation, using a few barebone methods. Our BC implementation will consist of three components:
(1) Dataset: Cartpole
(2) Model: FC Neural Network
(3) Loss: Binary Cross entropy LossTo demonstrate BC we’ve chosen a simple graphical environment in the Open AI gym, called cartpole. The agent consists of a cart set on a frictionless surface with a frictionless joint that attaches a pole on top. The goal of the agent is to balance this pole. It has a discrete action space: {push to the left - 0, push to the right - 1} and a continuous state space: {cart position - [-4.8, 4.8] , cart velocity - [-inf, inf] , pole angle - [-24, 24 (deg)], pole angular velocity - [-inf, inf]}.
To obtain expert demostrations, we quickly train Open AI’s PPO implementation and sample from it’s trained agent. Now, we are left with the supervised learning problem which is the crux of BC. We go about solving this supervised learning problem using a fully connected neural net with three layers follow by ReLU nonlinearities and a final sigmoid nonlinearity. Given the training data, we can now approximate a function that maps states to actions, which serves as your behaviorally cloned policy.
Although our expert PPO agent is familiar with the reward structure of the environment, we can achieve similar performance without knowing the underlying MDP. But, when our trained agent interacts with states not covered by the expert demostrator, it won’t know how to behave. This issue, refered to as distribution shift, can cause a compounding sequence of incorrect steps that wreck havoc. If a BC agent encounters a state that it is even slightly unfamiliar, it will take a wrong action, leading it towards a next state even more unfamiliar — diverging from the expert very easily. When it came to our specific task, we tried our best to engineer around this issue and others that arose — see below.
Engineering Choices and Code
During the process of training the behavioral cloning net, a few engineering tricks were required to get the clone working, listed below for reference.
(1) Adding a final sigmoid (i.e. not TanH or ReLU) nonlinearity to account for the binary actions and to avoid numerical instability (2) Generating more sample data from the expert if too few isn’t sufficient enough to cover the intricate expert behavior (3) Not making the model too deep to prevent overfitting (4) Performing a hyperparameter search on the learning rate
These steps above allowed the BC agent to transform from a cart that couldn’t even hold the pole up to one that can now balance it for multiple steps. In early experiments, I didn’t sample enough expert points to really learn the non-linear dynamics of the expert cartpole, so I needed to make sure to generate sufficient sample data. I also noticed my initial net was outputing actions that were integers outside the action space (i.e. -1 or 3), so I had to add the sigmoid to rescrict this behavior and improve numerical stabilty. Finally, I had to tune the model depth and learning rate to handle jittery behavior that was likely due to overfitting and convergence to local optimums, respectively. There are many more engineering methods I could continue pursuing to ensure better performance, but I stopped once I was able to demonstrate successful learned behavior with the clone.
'''
Imports
'''
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import gym
from stable_baselines.common.policies import MlpPolicy
from stable_baselines import PPO1
from stable_baselines.gail import generate_expert_traj
'''
Create Env and Train Expert
'''
env = gym.make('CartPole-v1')
model = PPO1(MlpPolicy, env, verbose=1)
model.learn(total_timesteps=250000)
model.save("ppo1_cartpole")
model = PPO1.load("ppo1_cartpole")
'''
Generate Expert Demonstrations
Specs:
No. of Trajectories: 1000
No. of State action Pairs: 479318
Model: PPO (taken from Open AI Baseline Implementation)
'''
size = 1000
generate_expert_traj(model, 'expert_cartpole', env = env , n_timesteps=0, n_episodes=size)
demos = np.load('expert_cartpole.npz', mmap_mode='r')
data_in = demos['obs']
data_out = demos['actions']
'''
Define BC Model as NN
Specs:
NN: 3 layers (4 each cells with ReLu) and Sigmoid on Output
Loss: BCE (Binary Cross Entropy)
'''
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(4, 4)
self.fc2 = nn.Linear(4, 4)
self.fc3 = nn.Linear(4, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.sigmoid(self.fc3(x))
return x
net = Net()
model = net
'''
Train BC Model
'''
criterion = nn.BCELoss()
learning_rate = [10, 1, 0.1, 0.01, 0.001, 0.0001]
#learning_rate that worke = [1.5]
for lr in learning_rate:
x = torch.from_numpy(data_in).to(torch.float32)
y = torch.from_numpy(data_out).to(torch.float32)
for t in range(200):
y_pred = model(x)
loss = criterion(y_pred, y)
print(t, loss.item())
model.zero_grad()
loss.backward()
with torch.no_grad():
for param in model.parameters():
param.data -= lr * param.grad
'''
Render BC Agent and Generate Gifs
'''
env = gym.make('CartPole-v1')
obs = env.reset()
#frames = []
T = 200
for t in range(T):
obs = torch.from_numpy(obs)
model.double()
action = model.forward(obs)
if action < 0.5:
action = 0
else:
action = 1
#print(action)
obs, rewards, dones, info = env.step(action)
#print(obs)
env.render()
time.sleep(.025)
#frames.append(env.render(mode="rgb_array"))PPO Expert
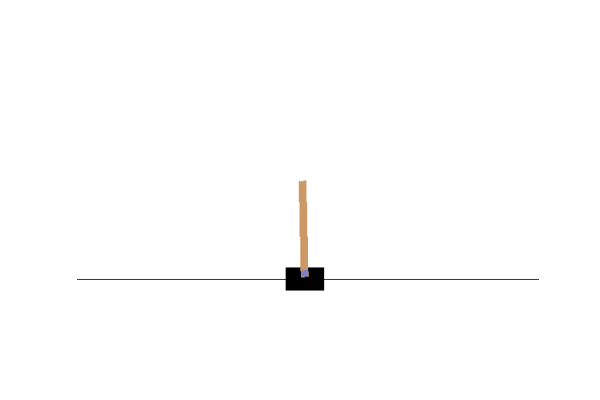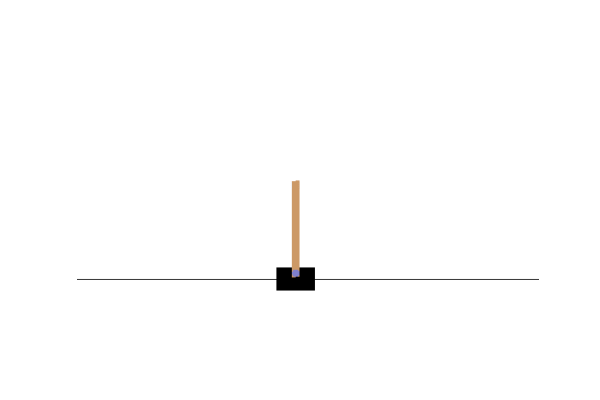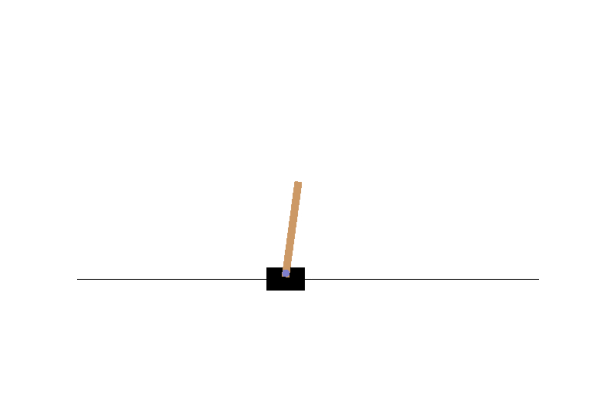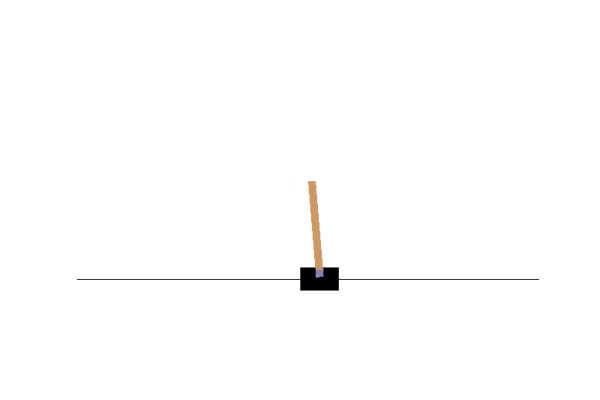
BC Clone
As you can see, it doesn’t do terribly well, it’s merely a budget PPO. However, with more model engineering, and cherry picked initialization data, you could see better results.
Parting Thoughts
If this material interests you, read more about Behavioral Cloning and other Imitation Learning methods in the references below. In addition, I would like to acknowledge a few people for their key contributions: (1) Charlie Snell for helping debug the BC Net and imparting his engineering experience with the gym and training agents (2) Aurick Zhou for explaining the intuition behind BC and it’s connection with MLE.
References
Survey paper on Imitation Learning. https://arxiv.org/pdf/1811.06711.pdf
Introduction to Probability by Bertsekas and Tsitsiklis. Example 3.11 on Buffon’s Needle and Chapt 9.1 on Classical Parameter Estimation
Wiki on Likelihood. https://en.wikipedia.org/wiki/Likelihood_function
BC Self-driving paper (ALVINN). https://papers.nips.cc/paper/1988/file/812b4ba287f5ee0bc9d43bbf5bbe87fb-Paper.pdf
First Alpha-go paper. https://www.nature.com/articles/nature16961
Imitation Learning github reopo. https://github.com/HumanCompatibleAI/imitation
PPO model documentation. https://stable-baselines.readthedocs.io/en/master/modules/ppo2.html
Dataset collection documentation. https://stable-baselines.readthedocs.io/en/master/guide/pretrain.html
Cartpole Tutorial. https://xaviergeerinck.com/post/ai/rl/openai-cartpole
OpenAI Gym Cartpole env. https://github.com/openai/gym/blob/master/gym/envs/classic_control/cartpole.py
Pytorch RL tutorial. https://pytorch.org/tutorials/intermediate/reinforcement_q_learning.html
Pytorch basics tutorial. https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html
Another pytorch basics tutorial. https://github.com/jcjohnson/pytorch-examples
Yet another pytorch basics tutorial. https://pytorch.org/tutorials/beginner/blitz/neural_networks_tutorial.html
Gym gif renderer. https://gist.github.com/botforge/64cbb71780e6208172bbf03cd9293553