
Alien Dreams: An Emerging Art Scene
In this blog post I document the evolution of this new art scene and share a bunch of cool artwork along the way.

In recent months there has been a bit of an explosion in the AI generated art scene.
Ever since OpenAI released the weights and code for their CLIP model, various hackers, artists, researchers, and deep learning enthusiasts have figured out how to utilize CLIP as a an effective “natural language steering wheel” for various generative models, allowing artists to create all sorts of interesting visual art merely by inputting some text – a caption, a poem, a lyric, a word – to one of these models.
For instance inputting “a cityscape at night” produces this cool, abstract-looking depiction of some city lights:

(source: @RiversHaveWings on Twitter)
Or asking for an image of the sunset returns this interesting minimalist thing:

(source: @Advadnoun on Twitter)
Asking for “an abstract painting of a planet ruled by little castles” results in this satisfying and trippy piece:

(source: @RiversHaveWings on Twitter)
Feed the system a portion of the poem “The Wasteland” by T.S. Eliot and you get this sublime, calming work:

(source: @Advadnoun on Twitter)
You can even mention specific cultural references and it’ll usually come up with something sort of accurate. Querying the model for a “studio ghibli landscape” produces a reasonably convincing result:

(source: @ak92501 on Twitter)
You can create little animations with this same method too. In my own experimentation, I tried asking for “Starry Night” and ended up with this pretty cool looking gif:

These models have so much creative power: just input some words and the system does its best to render them in its own uncanny, abstract style. It’s really fun and surprising to play with: I never really know what’s going to come out; it might be a trippy pseudo-realistic landscape or something more abstract and minimal.
And despite the fact that the model does most of the work in actually generating the image, I still feel creative – I feel like an artist – when working with these models. There’s a real element of creativity to figuring out what to prompt the model for. The natural language input is a total open sandbox, and if you can weild words to the model’s liking, you can create almost anything.
In concept, this idea of generating images from a text description is incredibly similar to Open-AI’s DALL-E model (if you’ve seen my previous blog posts, I covered both the technical inner workings and philosophical ideas behind DALL-E in great detail). But in fact, the method here is quite different. DALL-E is trained end-to-end for the sole purpose of producing high quality images directly from language, whereas this CLIP method is more like a beautifully hacked together trick for using language to steer existing unconditional image generating models.

A high-level depiction of how DALL-E’s end-to-end text-to-image generation works.
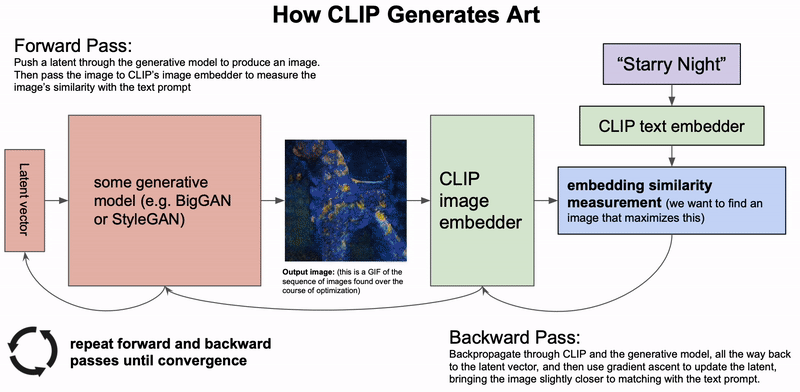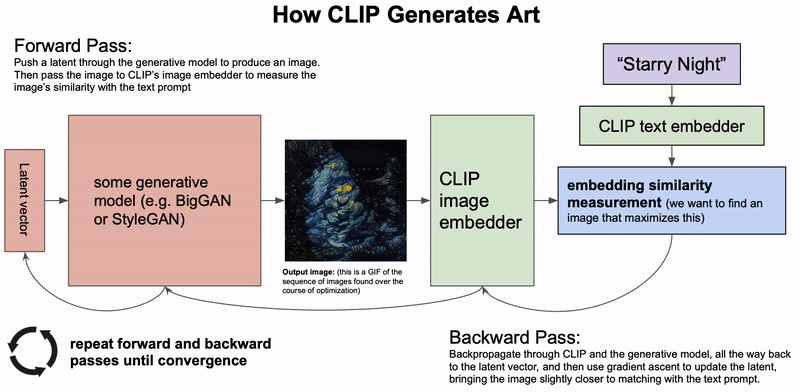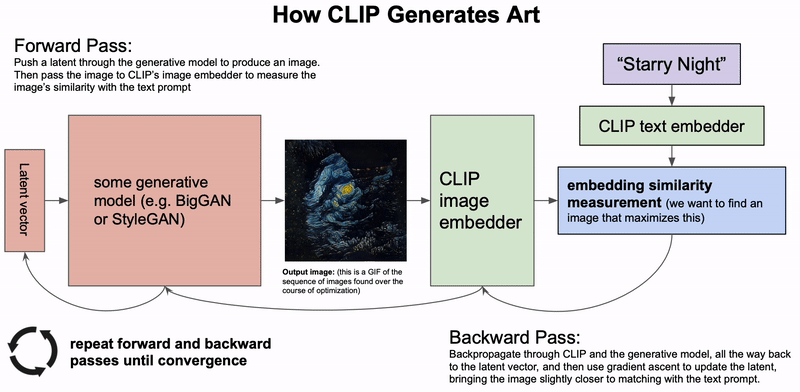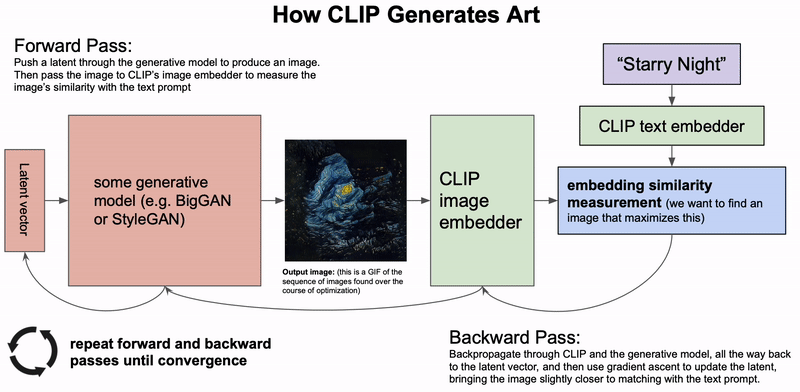
A high level depiction of how CLIP can be used to generate art.
The weights for DALL-E haven’t even been publicly released yet, so you can see this CLIP work as somewhat of a hacker’s attempt at reproducing the promise of DALL-E.
Since the CLIP based approach is a little more hacky, the outputs are not quite as high quality and precise as what’s been demonstrated with DALL-E. Instead, the images produced by these systems are weird, trippy, and abstract. The outputs are grounded in our world for sure, but it’s like they were produced by an alien that sees things a little bit differently.
It’s exactly the weirdness that makes these CLIP based works so uniquely artistic and beautiful to me. There’s something special about seeing an alien perspective on something familiar.
(Note: technically DALL-E makes use of CLIP to re-rank its outputs, but when I say CLIP based methods here, I’m not talking about DALL-E.)

Over the last few months, my Twitter timeline has been taken over by this CLIP generated art. A growing community of artists, researchers, and hackers have been experimenting with these models and sharing their outputs. People have also been sharing code and various tricks/methods for modifying the quality or artistic style of the images produced. It all feels a bit like an emerging art scene.
I’ve had a lot of fun watching as this art scene has developed and evolved over the course of the year, so I figured I’d write a blog post about it because it’s just so cool to me.
I’m not going to go in-depth on the technical details of how this system generates art. Instead, I’m going to document the unexpected origins and evolution of this art scene, and along the way I’ll also present some of my own thoughts and some cool artwork.
Of course I am not able to cover every aspect of this art scene in a single blog post. But I think this blog hits most of the big points and big ideas, and if there’s anything important that you think I might have missed, feel free to comment below or tweet at me.
CLIP: An Unexpected Origin Story
On January 5th 2021, OpenAI released the model-weights and code for CLIP: a model trained to determine which caption from a set of captions best fits with a given image. After learning from hundreds of millions of images in this way, CLIP not only became quite proficient at picking out the best caption for a given image, but it also learned some surprisingly abstract and general representations for vision (see multimodal neuron work from Goh et al. on Distill).
For instance, CLIP learned to represent a neuron that activates specifically for images and concepts relating to Spider-Man. There are also other neurons that activate for images relating to emotions, geographic locations, or even famous individuals (you can explore these neuron activations yourself with OpenAI’s microscope tool).
Image representations at this level of abstraction were somewhat of a first of their kind. And in addition to all of this, the model also demonstrated a greater classification robustness than any prior work.
So from a research perspective, CLIP was an incredibly exciting and powerful model. But nothing here clearly suggests that it would be helpful with generating art – let alone spawning the art scene that it did.
Nonetheless, it only took a day for various hackers, researchers, and artists (most notably @advadnoun and @quasimondo on Twitter) to figure out that with a simple trick CLIP can actually be used to guide existing image generating models (like GANs, Autoencoders, or Implicit Neural Representations like SIREN) to produce original images that fit with a given caption.
In this method, CLIP acts as something like a “natural language steering wheel” for generative models. CLIP essentially guides a search through the latent space of a given generative model to find latents that map to images which fit with a given sequence of words.
Early results using this technique were weird but nonetheless surprising and promising:
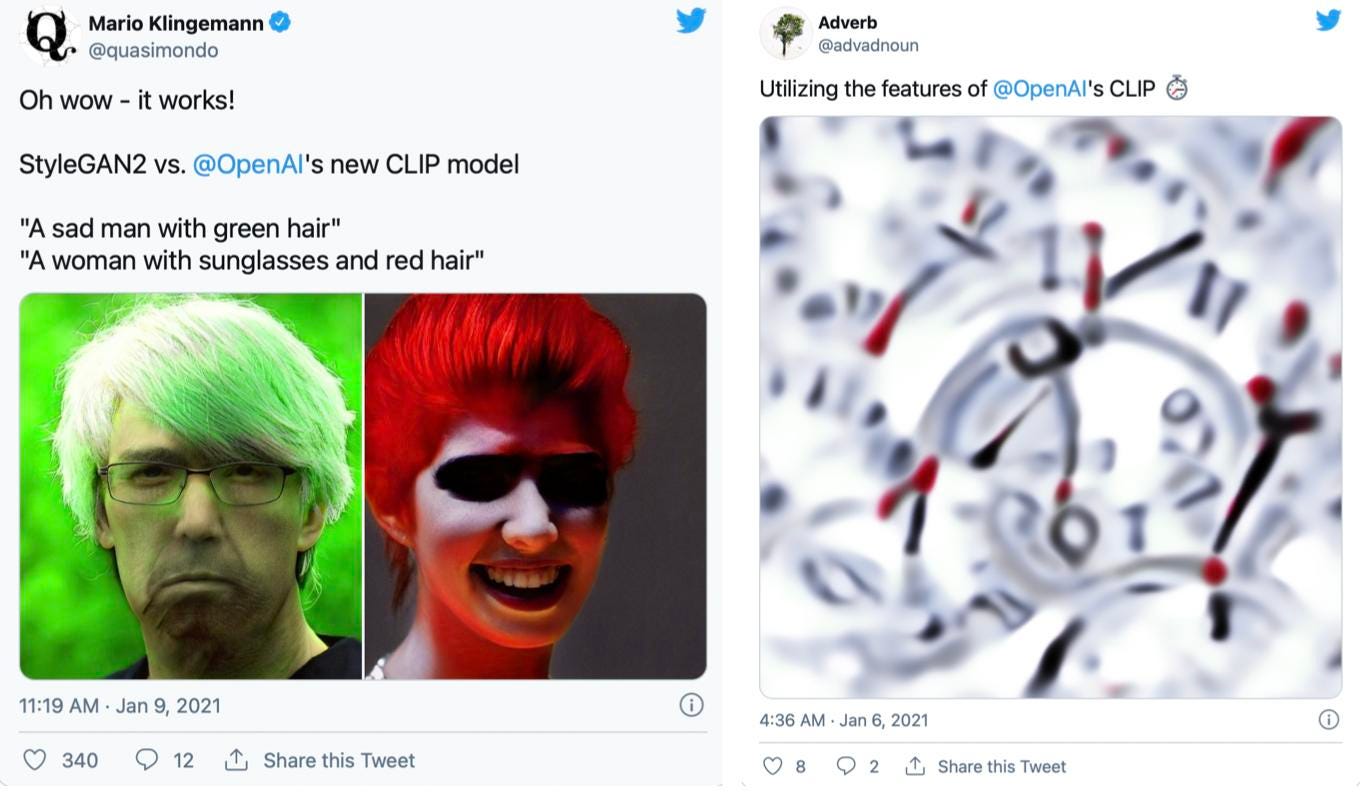
left – (source: @quasimondo on Twitter); right – (source: @advadnoun on Twitter)
The Big Sleep: Humble Beginnings
In just a couple weeks, there was a breakthrough. @advadnoun released code for The Big Sleep: a CLIP based text-to-image technique, which used Big GAN as the generative model.

(source: @advadnoun on Twitter)
In its own unique way, the Big Sleep roughly met the promise of text-to-image. It can approximately render just about anything you can put into words: “a sunset”, “a face like an M.C. Escher drawing”, “when the wind blows”, “the grand canyon in 3d”.
Of course, the outputs from The Big Sleep are maybe not everyone’s cup of tea. They’re weird and abstract, and while they are usually globally coherent, sometimes they don’t make much sense. There is definitely a unique style to artworks produced by The Big Sleep, and I personally find it to be aesthetically pleasing.

“a sunset” according to The Big Sleep (source: @advadnoun on Twitter)

“a face like an M.C. Escher drawing” from The Big Sleep (source: @advadnoun on Twitter)

“when the wind blows” from The Big Sleep (source: @advadnoun on Twitter)
But the main wonder and enchantment that I get from The Big Sleep does not necessarily come from its aesthetics, rather it’s a bit more meta. The Big Sleep’s optimization objective when generating images is to find a point in GAN latent space that maximally corresponds to a given sequence of words under CLIP. So when looking at outputs from The Big Sleep, we are literally seeing how CLIP interprets words and how it “thinks” they correspond to our visual world.
To really appreciate this, you can think of CLIP as being either statistical or alien. I prefer the latter. I like to think of CLIP as something like an alien brain that we’re able to unlock and peer into with the help of techniques like The Big Sleep. Neural networks are very different from human brains, so thinking of CLIP as some kind of alien brain is not actually that crazy. Of course CLIP is not truly “intelligent”, bit it’s still showing us a different view of things, and I find that idea quite enchanting.
The alternative perspective/philosophy on CLIP is a little more statistical and cold. You could think of CLIP’s outputs as the product of mere statistical averages: the result of computing the correlations between language and vision as they exist on the internet. And so with this perspective, the outputs from CLIP are more akin to peering into the zeitgeist (at least the zeitgeist at the time that CLIP’s training data was scraped) and seeing things as something like a “statistical average of the internet” (of course this assumes minimal approximation error with respect to the true distribution of data, which is probably an unreasonable assumption).
Since CLIP’s outputs are so weird, the alien viewpoint makes a lot more sense to me. I think the statistical zeigeist perspective applies more to situations like GPT-3, where the approximation error is presumably quite low.

“At the end of everything, crumbling buildings and a weapon to pierce the sky” from The Big Sleep (source: @advadnoun on Twitter)
“the grand canyon in 3d” according to The Big Sleep
Looking back, The Big Sleep is not the first AI art technique to capture this magical feeling of peering into the “mind” of a neural network, but it does capture that feeling arguably better than any technique that has come before.
That’s not to say that older AI art techniques are irrelevant or uninteresting. In fact, it seems that The Big Sleep was in some ways influenced by one of the most popular neural network art techniques from a foregone era: DeepDream.
Per @advadnoun (The Big Sleep’s creator):
The Big Sleep’s name is “an allusion to DeepDream and the surrealist film noir, The Big Sleep. The second reference is due to its strange, dreamlike quality” (source).
It’s interesting that @advadnoun partly named The Big Sleep after DeepDream because looking back now, they are spiritually sort of related.
DeepDream was an incredibly popular AI art technique from a previous generation (2015). The technique essentially takes in an image and modifies it slightly (or dramatically) such that the image maximally activates certain neurons in a neural network trained to classify images. The results are usually very psychedelic and trippy, like the image below.

an image produced by DeepDream (source).
Although aesthetically DeepDream is quite different from The Big Sleep, both of these techniques share a similar vision: they both aim to extract art from neural networks that were not necessarily meant to generate art. They dive inside the network and pull out beautiful images. These art techniques feel like deep learning interpretability tools that accidentally produced art along the way.
So in a way, The Big Sleep is sort of like a sequel to DeepDream. But in this case the sequel is arguably better than the original. The alien views generated by DeepDream will always be timeless in their own respect, but there’s something really powerful about being able to probe CLIP’s knowledge by prompting it with natural language. Anything you can put into words will be rendered through this alien dream-like lense. It’s just such an enchanting way to make art.
VQ-GAN: New Generative Superpowers
On December 17 2020, researchers (Esser et al.) from Heidelberg University, posted their paper “Taming Transformers for High-Resolution Image Synthesis” on Arxiv. They presented a novel GAN architecture called VQ-GAN which combines conv-nets with transformers in a way that optimally takes advantage of both the local inductive biases of conv-nets and the global attention in transformers, making for a particularly strong generative model.
Around early April @advadnoun and @RiversHaveWings started doing some experiments combining VQ-GAN and CLIP to generate images from a text prompt. On a high level, the method they used is mostly identical to The Big Sleep. The main difference is really just that instead of using Big-GAN as the generative model, this system used VQ-GAN.
The results were a huge stylistic shift:

“A Series Of Tubes” from VQ-GAN+CLIP (source: @RiversHaveWings on Twitter)

“The Yellow Smoke That Rubs Its Muzzle On The Window-Panes” from VQ-GAN+CLIP (source: @RiversHaveWings on Twitter)

“Planetary City C” from VQ-GAN+CLIP (source: @RiversHaveWings on Twitter)

“Dancing in the moonlight” from VQ-GAN+CLIP (source: @advadnoun on Twitter)

“Mechanic Desire” from VQ-GAN+CLIP (source: @RiversHaveWings on Twitter)

“Mechanic Desire” from VQ-GAN+CLIP (source: @RiversHaveWings on Twitter)

“a tree with weaping branches” from VQ-GAN+CLIP (source: @advadnoun on Twitter)
The outputs from VQ-GAN+CLIP tend to look less painted than The Big Sleep and more like a sculpture. Even when the images are too abstract to be real, there’s a certain material quality to them that makes it seem as if the objects in the images could have been crafted by hand. At the same time, there’s still an alien weirdness to it all, and the aura of peering into a neural network and seeing things from its viewpoint is most definitely not lost here.
Just swapping out the generative model from Big-GAN to VQ-GAN was almost like gaining a whole new artist with their own unique style and viewpoint: a new lens for seeing the world through CLIP’s eyes. This highlights the generality of this CLIP based system. Anytime a new latent-generative model is released, it can usually be plugged into CLIP without too much trouble, and then suddenly we can generate art with a new style and form. In fact, this has already happened at least once: less than 8 hours after DALL-E’s dVAE weights were publically released, @advadnoun was already Tweeting out art made with dVAE+CLIP.
The Joys of Prompt Programming: The Unreal Engine Trick
We’ve seen how switching generative models can dramatically modify the style of CLIP’s outputs without too much effort, but it turns out that there’s an even simpler trick for doing this.
All you need to do is add some specific key-words to your prompt that indicate something about the style of your desired image and CLIP will do its best to “understand” and modify its output accordingly. For example you could append “in the style of Minecraft” or “in the style of a Cartoon” or even “in the style of DeepDream” to your prompt and most of the time CLIP will actually output something that roughly matches the style described.
In fact, one specific prompting trick has gained quite a bit of traction. It has become known as the “unreal engine trick”.

(source: @arankomatsuzaki on Twitter)
It was discovered by @jbustter in EleutherAI’s Discord just a few weeks ago that if you add “rendered in unreal engine” to your prompt, the outputs look much more realistic.

(source: the #art channel in EleutherAI’s Discord)
Unreal Engine is a popular 3D video game engine created by Epic Games. CLIP likely saw lots of images from video games that were tagged with the caption “rendered in Unreal Engine”. So by adding this to our prompt, we’re effectively incentivizing the model to replicate the look of those Unreal Engine images.
And it works pretty well, just look at some of these examples:

“a magic fairy house, unreal engine” from VQ-GAN+CLIP (source: @arankomatsuzaki on Twitter)

“A Void Dimension Rendered in Unreal Engine” from VQ-GAN+CLIP (source: @arankomatsuzaki on Twitter)
“A Lucid Nightmare Rendered in Unreal Engine” from VQ-GAN+CLIP (source: @arankomatsuzaki on Twitter)
CLIP learned general enough representations that in order to induce desired behavior from the model, all we need to do is to ask for it in the prompt. Of course, finding the right words to get the best outputs can be quite a challenge; after all, it did take several months to discover the unreal engine trick.
In a way, the unreal engine trick was a breakthrough. It made people realize just how effective adding keywords to the prompt can be. And in the last couple weeks, I’ve seen increasingly complicated prompts being used that are aimed at extracting the highest quality outputs possible from CLIP.
For example, asking VQ-GAN+CLIP for “a small hut in a blizzard near the top of a mountain with one light turn on at dusk trending on artstation | unreal engine” produces this hyper-realistic looking output:

(source: @ak92501 on Twitter)
Or querying the model with “view from on top of a mountain where you can see a village below at night with the lights on landscape painting trending on artstation | vray” gives this awe-inspiring view:

(source: @ak92501 on Twitter)
Or “matte painting of a house on a hilltop at midnight with small fireflies flying around in the style of studio ghibli | artstation | unreal engine”:

(source: @ak92501 on Twitter)
Each of these images looks nothing like the VQ-GAN+CLIP art we saw in the previous section. The outputs still have a certain surreal quality to them and maybe the coherence breaks down at a few points, but overall the images just pop like nothing else we’ve seen so far; they look more like edited photographs or scenes from a video game. So it seems that each of these keywords – “trending on artstation”, “unreal engine”, “vray” – play a crucial role in defining the unique style of these outputs.
This general paradigm of prompting models for desired behavior is becoming known as “prompt programming”, and it is really quite an art. In order to have any intuition as to what prompts might be effective, you need some clue as to how the model “thinks” and what types of data the model “saw” during training. Otherwise, prompting can be a little bit like dumb luck. Although hopefully, in the future, as models get even larger and more powerful, this will become a little bit easier.
This is Just The Beginning
In this blog post I’ve described some of the early milestones in the evolution of CLIP-based generative art. But by no means was this an extensive coverage of the art that people have been able to create with CLIP. I didn’t even get around to talking about the super cool work that’s been done with StyleGAN+CLIP or the really interesting CLIPDraw work or even the saga of experiments done with DALL-E’s dVAE+CLIP. I could go on and on, and the list of new methods for creating art with CLIP is expanding each week. In fact, it really feels like this is just the beginning; there is likely so much to improve and build upon and so many creative discoveries yet to be made.
So if this stuff is interesting to you, and you’d like to learn more about how these CLIP based art systems work, or even if you just want to keep up with some of the most innovative artists in this space, or if you want to try your own hand at generating some art, be sure to checkout the resources below.
References, Notebooks, and Relevant Twitter Accounts
References
(see the captions below each piece of artwork for its corresponding reference; all images without references are works that I created)
Notebooks
(you can use these Colab notebooks to make your own CLIP based art; just input a prompt. They each use slightly different techniques. Have fun !)
(Note: if you are unfamiliar with Google Colab, I can recommend this tutorial on how to operate the notebooks.)
Relevant Twitter Accounts
(these are all twitter accounts that frequently post art generated with CLIP)