
What are MDPs? And how can we Solve them?

by Surya Vengadesan
With deep reinforcment learning’s success in beating humans at games including Go, Dota 2, and even Poker, there is a lot of excitement around the field and people want to understand its algorithms from the ground up. In this blog post, we will do just that. We will explore a fundamental building block of deep RL: Markov Decision Processess — a framework that models how an agent behaves and learns from it’s environment. In particular, we will lay out the theory of MDPs and explore approximate methods for solving them.
Mr. Markov Navigating College
Now, let’s walk through MDPs by studying a specific agent. Specifically, an agent is an entity that interacts within its environment and interatively learns how to best act within the environment. For our example, Mr. Markov will be our agent; he is an undergraduate studying mathematics. Markov needs to make many decisions while in college (his environment). In a typical day, Markov studies for his probability theory class, sleeps in his bed, or socializes with his friends in hour long chunks. Markov is faced with a problem. Some days Markov is incredibly tired from staying up to finish his problem sets or feels stir-crazy from sitting at his desk for hours on end. Therefore, Markov needs a process to help him navigate through his daily decisions in hopes to bring him peace.
Modeling Mr. Markov’s World
In this blog post we are going to help this poor student, by laying out a Markov Decision Process to model his world, then figure out what actions he should take in his best self-interest. Markov, at any given time, could be in one of a finite number of states. Let’s denote these in a set called the state space:
In addition, in any given state he could decide from a set of actions. Let’s denote these in a set called the action space:
In our model world, at every hour, Markov can perform one of these three actions from any of the three states. We shall demarcate these hours of the day by variable ttt. By taking an action at a specific state at a specific time t, Markov will end up in a new state s′∈S. We shall also define a set of non-negative probabilities for each state-action pair and it’s resulting action, P(s′∣s,a)≥0, and with any probability distribution these must add to 1: Σs′ P(s′∣s,a)=1.
Now, we ask Markov a question: “What is your purpose? What do you value?.” Markov, an aspiring future graduate student in mathematics, responds, “To one day teach probability theory to other students and perform original research within the field.” To help this aspiring future probability theorist, let’s add a few more definitions to his decision-making framework, that can help quantify what he values. For each state-action pair and associated next state, we assign a scalar reward r(s′∣s,a)=c. We ask Markov a follow up question: “What’s your plan? How do you plan on getting into graduate school?” He responds, “I’m going to study, study a lot.” Now, to help Markov on his journey, we add a few extra formalisms. First we formalize his plan into a function, and call it a policy function π(a∣s) that maps every state with a specific action to take.
To sum it up, say he’s in state s1=studying, and he decided to take the action of a1=messaging a friend according to his policy. Given (s1,a1), he now has the following probabilities at ending up the following states after completing the action,
which add up to 1 as defined previously. Let’s also define a set of rewards that we believe best align with what Markov says he values. We can assign real values rewards to each state he next ends up in after performing action a1 in state s1,
Together, we have incorporated stochastic behavior and measures of value and into the framework, since each state-action pair is now mapped to a probability distribution and a set of rewards that uniquely determine each next possible state. In essence, we have just laid out the mathematical formalism for MDPs, which not only helps Markov, but more generally exists as a tool that lies at the core of many control theory applications, including reinforcement learning.
Recap of Definitions
We have defined 4 quantities making up the tuple <S,A,T,R>, which includes a state space, an action space, a transition function, and a reward function. In our specific example with Markov, we have 3 states, 3 rewards, and a transition and reward function that map all pairs of state-action transitions (s’|a, s) with an associated probability reward, totalling to 27 scalars each. What we have just defined above, is referred to as a finite MDP, because element of the tuple consists of finite sets. Below is a subset of the MDP over an arbitrary state action pair (si,ai).
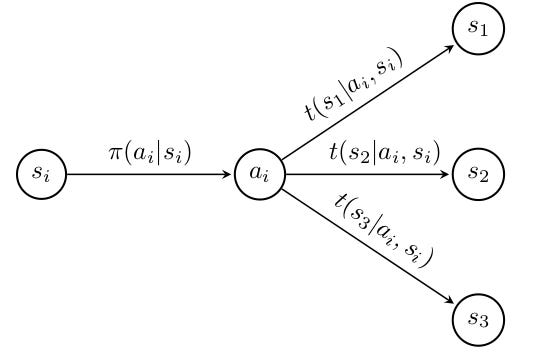
Using this structure, we would like to figure out what actions we should take to get the highest reward; fortunately, there exist proven algorithms to do exactly this. We will soon attempt to solve for an optimal policy function π(⋅) using said algorithms in Markov’s world. Through our specific example, we are attempting to solve the old, and suprisingly relevant meme (below), but with extreme precision due to the beauty of finite MDPs.
Before, we reach the solution, however, we need a few more tools defined below.
More Fun Functions
Given these well defined transition dynamics and rewards of Markov’s model world, we can define two additional functions. The first is the state-value function. This is determined by the state Markov is currently in and also his current policy function:
This can be interpreted as the long-term expected reward that Markov will receive from currently being in state sss and acting according to his plan. Here, we have two random variables that St and Rt that model the state and reward the agent will be in and recieve, at time step t, if it follows the policy defined by π(⋅). We have also introduced a new variable γ which we call the discount rate, that can be any value from 0≤γ≤1. The term in the expectation expands out to this form:
In essence, the value of the reward gained by taking an action and landing in a new state in the future, is being reduced by a multiple of γ with each time step that passes. This answers the question on how much a given reward is depriciated each ttt time step into the future, before it has been obtained.
Altogether, the state-value function vπ(⋅) allows us to help Markov gauge the value he obtains from his tentative plan that we have formalized by the policy function π(⋅). Now, the curious Markov asks us, “Well, assume I’m working on my probability pset and decide to go read War and Peace by Leo Tolstoy, is that a good idea?” To answer this, let’s add our final function to put Markov’s mind at rest. Let’s call it the action-value function qπ(s,a), which is the expected return in rewards he receives, computed similarly to the state-value function, but incorporating the reward from an initial action aaa instead of action π(s):
This seemingly insignificant distinction will help us when it comes time to compute the optimal policy π*(⋅). Together, the state-value and action-value functions, are called the Bellman equations. We, will now solve for the value of these Bellman equations at each state or state-action pair, using two fundamental algorithms.
Solving via Policy Iteration
The first main algorithm used to solve finite MDPs is called Policy Iteration. This algorithm iterates between two steps. The first step is to evaluate the value function for all states of an MDP given an arbitrary policy. This is commonly referred to as policy evaluation. The second step is to consider for each state, whether taking action a≠π(s) (not part of the policy) can improve the overall expected return. This is commonly referred to as policy evaluation. The algorithm loops through these steps, finding a better policy at each iteration until convergence.
Now, we shall implement Markov’s model world using python and numpy. We follow the standard algorithm implementation outlined in Richard Sutton’s RL textbook. However, we make a few simplificiations for a quick build. (1) Our model only has 1 reward per (s’, s, a) pairs, while others allow for a distribution over rewards (2) We are searching to solve for a deterministic policy, while others can solve for a stochastic policy (3) Instead of defining 56 carefully engineered rewards and transitions, we assign fixed values (4) To assure convergence of our expected long term reward (to avoid values approaching infinity), so we include a discount rate of 0.85.
We first need to make a few imports and initialize our finite MDP.
import numpy as np
import matplotlib.pyplot as plt
import math
states = 3 #Number of States
actions = 3 #Number of Actions
rewards = 3 #Number of Rewards per State-action Pair
g = 0.85 #Discount Rate - gamma
v_s = [0, 0, 0] #State-value Function
pi = [0, 0, 0] #Deterministic Policy Function
theta = 1 #Hyperparameter
np.random.seed(0) #Random seed used to initalize Reward Function
R = 100 * np.random.rand(3, 3, 3) #Reward Function: intialize a 3x3x3 tensor of random values from 0 to 100
T = np.full((3,3,3), 1/3) #Transition Function: intialize a 3x3x3 tensor of 1/3s
PI = [] #List to keep track of value function for Policy Iteration
VI = [] #List to keep track of value function for Value Iteration
print(R) #Our specific Reward Function
#Randomly Initialized Reward Function
[[[54.88135039 71.51893664 60.27633761]
[54.4883183 42.36547993 64.58941131]
[43.75872113 89.17730008 96.36627605]]
[[38.34415188 79.17250381 52.88949198]
[56.80445611 92.55966383 7.10360582]
[ 8.71292997 2.02183974 83.26198455]]
[[77.81567509 87.00121482 97.86183422]
[79.91585642 46.14793623 78.05291763]
[11.82744259 63.99210213 14.33532874]]]Now for the implementation of Policy Iteration, which initializes an arbitraty policy and state-value function, then iterates between policy evaluation and policy improvement stages.
def policy_iteration(pol, val, thres):
#Initialize Policy and Value Function
policy = pol
threshold = thres
v_s_init = val
PI.append(v_s_init.copy())
#Run first iteration of PE to evaluate your arbitrary policy
value = policy_evaluation(pi, v_s_init, threshold)
PI.append(value.copy())
#Run first iteration of PI to find actions that might prove it
policy_stable, policy = policy_improvement(pi, value)
#Repeat PE and PI, until no change in policy improves performance (i.e. policy_stable = True)
while policy_stable == False:
value = policy_evaluation(policy, value, threshold)
PI.append(value.copy())
policy_stable, policy = policy_improvement(policy, value)
return policy, value
def policy_evaluation(pol, val, thres):
policy = pol
threshold = thres
v_s_init = val
delta = math.inf
#Evalute accuracy until Delta drops below specified threshold value
while delta >= threshold:
delta = 0
#Compute expected return for each state, given the current policy
for s in range(states):
v = v_s_init[s]
E_r = 0
for s_p in range(states):
E_r += T[s, policy[s], s_p]*(R[s, policy[s], s_p] + g*v_s_init[s_p])
v_s_init[s] = E_r
delta = max(delta, abs(v - v_s_init[s]))
return v_s_init
def policy_improvement(pol, val):
policy_stable = True
policy = pol.copy()
v_s_init = val
for s in range(states):
old_a = pol[s]
v = v_s_init[s]
E_r = []
#Evalute expected value of each state and action pair
for a in range(actions):
e_r = 0
for s_p in range(states):
e_r += T[s, a, s_p]*(R[s, a, s_p] + g*v_s_init[s_p])
E_r.append(e_r)
#Select action the maximizes expected value
new_a = E_r.index(max(E_r))
#Compare if action that maximizes expected value is action specified by current policy
if(old_a != new_a):
#If not, modify policy and report stability to false, to ensure PI evalutes new policy
policy[s] = new_a
policy_stable = False
return policy_stable, policy
#Run Algorithm
new_pi, new_v = value_iteration(pi, v_s, theta)Algorithm Output:
By running this algorithm, we obtain the optimal state-value function and optimal policy shown above. Now this example is clearly idealistic, we are given the states, actions, and rewards. In the real world we don’t have this, and real world problems are typically much more complicated. Figuring out how to solve more complex, obscure problems is an open challenge that the field faces to this day. In short, MDPs solve real-world problems only as best as you can model problems in the first place. Therefore, although we may not be able gaurantee that our policy will help Markov in the real-world, we hope that the theoretical implications can provide insight into his decision making.
Solving via Value Iteration and More
Now, let’s attempt to find the optimal policy of out student’s Markov’s work using Value Iteration. The structure of this algorithm is very similar to Policy Iteration, but differs slightly. Instead of iterating back and forth between improvement and evaluation in Policy Iteration, Value Iteration performs a single iteration of a pseudo policy evaluation, where it additionally sweeps over the action space and perform a max operation to return the optimal state-value function and policy function upon completion.
def value_iteration(pol, val, thres):
#Initialize Policy and Value Function
policy = pol
threshold = thres
v_s_init = val
VI.append(v_s_init.copy())
delta = math.inf
#Loop until delta reaches specified threshold
while delta >= threshold:
delta = 0
#Evalute expected value of each state and action pair
for s in range(states):
v = v_s_init[s]
E_r = []
for a in range(actions):
e_r = 0
for s_p in range(states):
e_r += T[s, a, s_p]*(R[s, a, s_p] + g*v_s_init[s_p])
E_r.append(e_r)
#Update policy with action that maximizes return
policy[s] = E_r.index(max(E_r))
#Update new state-value function accordingly
v_s_init[s] = max(E_r)
delta = max(delta, abs(v - v_s_init[s]))
I.append(v_s_init.copy())
return policy, v_s_init
#Run Algorithm
new_pi, new_v = value_iteration(pi, v_s, theta)Algorithm Ouput:
By running this algorithm, we obtain the optimal state-value function and optimal policy shown above. Overall, both methods follow different paths to reach the same solution, each carefully designed to use the Bellman equations to better understand the MDP.
Conclusion
This blog only covers the basics, and there is much more to explore in MDP theory. For example, there exists many extensions and generalizations to this framework, such as the partially observed or continous cases, studied by mathematicians and engineers alike. If this blog interested you and you want to dive deeper into algorithms for solving finite, discrete markov chains, then take a look at the references for a more detailed treatment of the topic.
References and Future Readings
Key Survey Reads
Introduction in Reinforcment Learning by Sutton and Barto, Chapters 3 and 4*
Probability in Electrical Engineering and Computer Science by Jean Walrand, Chapters 11 and 12
Dynamic Programming and Markov Processes by Ronald Howard
Read Bibliographical and Historial Remarks for a deeper dive
Related Slides and Class Sites
https://web.stanford.edu/class/cme241/lecture_slides/rich_sutton_slides/5-6-MDPs.pdf
https://inst.eecs.berkeley.edu/~cs188/sp20/assets/lecture/lec10.pdf
https://people.eecs.berkeley.edu/~pabbeel/cs287-fa12/slides/mdps-exact-methods.pdf
https://www.cse.iitb.ac.in/~shivaram/resources/ijcai-2017-tutorial-policyiteration/tapi.pdf
https://homes.cs.washington.edu/~todorov//courses/amath579/MDP.pdf
https://www.cs.mcgill.ca/~dprecup/courses/AI/Lectures/ai-lecture16.pdf