
Teaching the Brain to Discover Itself

By Ruchir Baronia

💡 In this blog post, we deep dive into the intersection between Machine Learning (ML) and Neuroscience. In doing so, we will familiarize ourselves with a multivariate approach of classifying neuroimaging data to identify behavior, predict neurodegenerative diseases, and more. What follows is a discussion of the applications, practicality, and ethical basis of neuroimaging analysis through Machine Learning.
Introduction
The human brain consists of 86 billion neurons 1, all collaborating to form our thoughts, emotions, and memories. It can learn languages, design machines, and direct complex surgical procedures. What the brain hasn’t been able to do is process itself. After centuries of research, scientists barely understand how our brains really work. Ironically, the human brain is an enigma to itself. That’s about to change.
What if, by analyzing just one, single picture of a brain, we could unravel its inner workings, even revealing subconscious thoughts and hidden feelings? It sounds like science fiction, but there is an entire subset of researchers inching closer to doing just that. They sit at the intersection of neurosicence and machine learning. Together, they’re figuring out the brain using technology that mimics the brain.
Road map
This post provides a comprehensive introduction into the sphere of neuroimaging, and its corresponding methods of Machine Learning Classification. The discussion follows as so:
1. Overview of Neuroimaging
An emphasis on the rising popularity of the field, as well as an introduction to the fMRI.
2. Past Innovations
A brief historical analysis of computational neuroscience, involving a deep-dive into Non-ML Brain-Computer Interfaces. By first understanding how conventional devices in the field have operated, we can form a better appreciation of the developments leading up to current ML devices, allowing us to truly appreciate the intersection of ML and Neuroscience.
3. An ML Approach
*Expanding on our discussion of Brain-Computer Interfaces, we zoom into the present, introducing ourselves to Multi-Voxel Pattern Classification, a form of multivariate analysis for brain scan data. This introduction will include a brief digression for beginners to refresh on classification as a principle.*
4. Classification Analysis: Limitations & Implications
*A comprehensive elaboration of Multi-Voxel Pattern Classification, including an analysis of both its limitations and implications.*
5. The Ethical Basis
Equipped with a high-level understanding of multi-voxel pattern classification, we discuss its ethical implications. Is extracting the thoughts from someone’s brain be morally wrong?
6. The Perpetual Cycle of Progress
A discussion of the mutually reinforcing nature of Neuroscience and Machine Learning.
5. Conclusion
A summary of what has been previously discussed.
Overview
Recently, engineers have begun to apply common machine learning algorithms to brain imaging data to discover patterns of how we think and behave. Using these algorithms, researchers are now able to distinguish individual cognitive processes—as well as uncover signs of neurological deterioration— by analyzing brain scan data.
Rising Popularity
Conventionally, medical workers embody a “manual” approach to processing brain scan images by simply analyzing them visually. A manual analysis, however, is not only tedious, but also generally produces day-to-day error rates of around 3-5%15! As such, ML has recently taken the spotlight in performing such analyses.
👩⚕️ Note: this is not to say that machine learning algorithms should replace medical workers or neuroscientists. Instead, by potentially providing greater speed and accuracy, such algorithms may complement experts by giving them the chance to refocus their manual attention on items of greater urgency.
The attention given to the intersection of neuroscience and machine learning has drastically proliferated. 16
💡 A cognitive state is any neurological experience, such as looking at a car or lifting a hand. Our end goal in this field is to extract cognitive states from brain imaging data.
Neuroimaging-based classification involves labeling images of brain scans with their respective cognitive state, and training a classification model using this labeled data. Upon doing so, the model should be able to classify cognitive states from images of brain scans (for a more detailed explanation, see Classification Algorithms or keep reading). Thus, researchers are able to build intelligent algorithms that can effectively interpret an individual’s cognitive state just by analyzing a relevant brain scan image.
Scientists have also begun to use Deep Learning algorithms to automatically learn from raw, unlabeled data. In this blog post, however, we will focus on the simpler subfield of supervised classification algorithms using labeled data.
💡 Supervised learning is the machine learning task of learning a function that maps an input to an output based on example input-output pairs. 17
The labeled, brain imaging data that we will use to extract our cognitive states from is known as fMRI data.
fMRI
Before delving into the various Machine Learning methods used to analyze the brain, it’s essential to introduce how this data is represented. In this article, we will primarily be familiarizing ourselves with fMRI data.
Note: fMRI is just one way to represent brain imaging data. For more on the different neuroimaging modalities, see this review. This post will focus exclusively on fMRI.
🧠 fMRI stands for Functional Magnetic Resonance Imaging and aims to “infer brain activity by assessing changes in brain circulation” 2
In essence, fMRI scans map brain activity by identifying regions with differences in blood flow. More blood flow is typically correlated with greater neural activity, allowing researchers to pinpoint what parts of the brain correlate to what behaviors.
An example of fMRI data. 2 The colors in the brain scan represent amounts of Blood Flow, and clearly are correlated with differences in stimulus. What if we tried to classify exactly what situations cause different parts of the brain to “light up?” Would be able to read minds?
For more on fMRI, read more here. For the scope of this blog post, however, we will consider the specifics of fMRI an abstraction, and purely focus on the implications of an ML-based analysis of such.
Past Innovations
Non-ML Brain-Computer Interfaces
Although the introduction of Machine Learning in neuroscience is fairly recent, the intersection of neuroscience and computation is not. Preceding our discussion of ML applications in neuroimaging data, we introduce a historic overview of older Brain Computer Interfaces (BCI’s). Relying on more traditional forms of computation, these older adaptations of BCI’s aim to, effectively, “read an individual’s mind” to change the state of a physical device.
By first understanding how conventional devices in the field have functioned, we can form a better appreciation of modern developments involving ML, allowing us to truly appreciate the intersection of ML and Neuroscience.
💡 Brain Computer Interfaces (BCI) are direct pathways between the brain and another device. They aim to allow a human to control an electronic device through thought. BCI’s have many different applications, but the phrase BCI here is being used to describe older BCI’s that do not utilize much Machine Learning. We adapt this term in such a way to better highlight a chronological shift of focus in computational neuroscience.
How is this possible? In essence, instead of decoding what the user is thinking, the user is trained to control one specific part of their mind. At heart, the user and BCI work together to convey a message. Older BCIs take this approach of trial and error to teach the individual to think in a way such that their brain signals are recognizable by the device. Such devices have been used to spell words, move cursors accurately, and even perform actions with a robotic arm. 2,4
💡 Classification, in this context, involves finding patterns in fMRI data and drawing links between such patterns and distinguishable cognitive states. Classifying an image with a corresponding mental state can be informally thought of as mind reading.
Interestingly enough, the goals of this field were roughly the reverse—historically—of what we aim to do now with newer ML classification analyses. Whereas modern advancements aim to train models to classify cognitive states from brain scan data, BCIs have historically been developed to respond to predefined mental states that the user would consciously place themselves in, often after being trained to think a certain way. Notice the distinction—in the modern approach, the device is being trained, while in the old approach, the user is. Although these older BCI’s are sophisticated and applicable in the field of computational neuroscience, they fail to extensively interpret or classify a mental state or behavior. Instead, they are limited to responding to a specific brain signal as input.
An explanation of the components of a BCI system. ^2,^ After brain signals are digitized and translated, they are used to control another device, examples of which are shown on the right.
💭 Here, we discuss older goals in the field not only to provide a historical analysis of previous interdisciplinary work in neuroscience and computation, but also to highlight the clear juxtaposition in the approaches of traditional computation—embodied through older BCIs—and modern computation—embodied through newer ML classification algorithms.
Equipped with more familiarity in the field of computational neuroscience, we can finally discuss machine learning classifiers of neuroimaging data.
An ML Approach: Multi-Voxel Pattern Classification
🔑 The key question to answer in analyzing neuroimaging data is whether or not we can successfully decipher one’s cognitive state, mental behaviors, or neurological health using ML classification methods.
💡 Voxel: A 3D unit, similar to a pixel, of a brain scan, embedding brain signals. Think of it as a chunk of brain tissue. A volumetric pixel.
Traditionally, analyzing fMRI scans embodied looking into separate brain voxels, one at a time, and identifying patterns between cognitive behavior and those individual voxels. This approach can be referred to as a single-voxel analysis technique.
Here, the yellow square represents a single voxel, and the graph represents its activation. 5 *
However, the brain is incredibly complex and interconnected. As such, it’s often beneficial to treat it as one interconnected item—or, more reasonably, a collection of a few major interconnected items—as opposed to a collection of individual, self-sufficient pieces. This introduces us to the distinction between a univariate and multivariate analysis.
Univariate vs Multivariate Analysis
In the context of neuroimaging analyses, a Univariate analysis considers only one decision variable at a time, such as one single voxel in a brain scan image. On the other hand, a multivariate technique would look at patterns throughout the entire image, taking into account the interconnectedness of the brain and the activation of multiple voxels.
Recently, scientists have begun to take into account the brain’s “full spatial pattern of activity”, rather than following the conventional strategy of interpreting individual regions of the brain. 4 Doing so has significant advantages. Put simply, by analyzing a plethora of brain regions at once, the “weak information available at each location” can be accumulated in an efficient way to form complete cognitive interpretations. 4 The differences between single and multi-voxel approaches is not the focus of this blog post, but if you are interested in a more detailed comparison, see this paper.
”The shift of focus away from conventional location-based analysis strategies towards the decoding of mental states can shed light on the most suitable methods by which information can be extracted from brain activity.”4
It’s clear that a multivariate analysis is beneficial in performing a comprehensive analysis of the brain, but how exactly does this multivariate analysis work?
Methods of Multi-Voxel Pattern Classification
A pattern-based classification problem revolves around the following question, ‘How reliably can patterns of brain activation indicate or predict the task in which the brain is engaged or the stimulus which the experimental participant is processing?’’14
Like a traditional classification problem, multi-voxel pattern classification generally falls into four basic steps. These steps, and the corresponding image below, are further outlined in the relevant paper in Trends in Cognitive Sciences6
Feature Selection: We first select the appropriate voxels for classification. Notice here we say voxels, not voxel, because this is a multi-voxel pattern classification.
This step is actually incredibly important, because selecting too many irrelevant voxels can add noise to our data. Selecting too few relavent voxels will make it difficult to draw concrete classifications. There are a plethora of ways to select the right features, such as performing a secondary single-voxel analysis to identify which voxels to track in the primary multi-voxel analysis. Other methods of feature selection are out of scope of this blog post.
Pattern Assembly Once we know which voxels to consider, it’s time to label our brain scans with their corresponding cognitive states. In essence, this step aims to sort the imaging data into bins by labeling each brain scan with the cognitive state it reflects. After labeling the fMRI scans around their respective experimental conditions, our labeled data is ready to be used to train a model.
Classifier Training We will now use this labeled data to train our classification algorithm to predict unseen brain scan data in the future. Put simply, this step involves teaching our computer to recognize a cognitive state from a brain scan. After feeding our labeled data into a classification algorithm, it will produce a predictive function that can recognize the cognitive state an unseen brain scan reflects. In other words, we are building a model that can recognize distinct voxel patterns by deducing the experimental conditions that sparked them.
Generalization Testing We then test our classifier on a new pattern of brain activity, and see if it can determine what cognitive activity corresponds to the pattern. Here, we can tweak our approach if the model does not meet our standards.
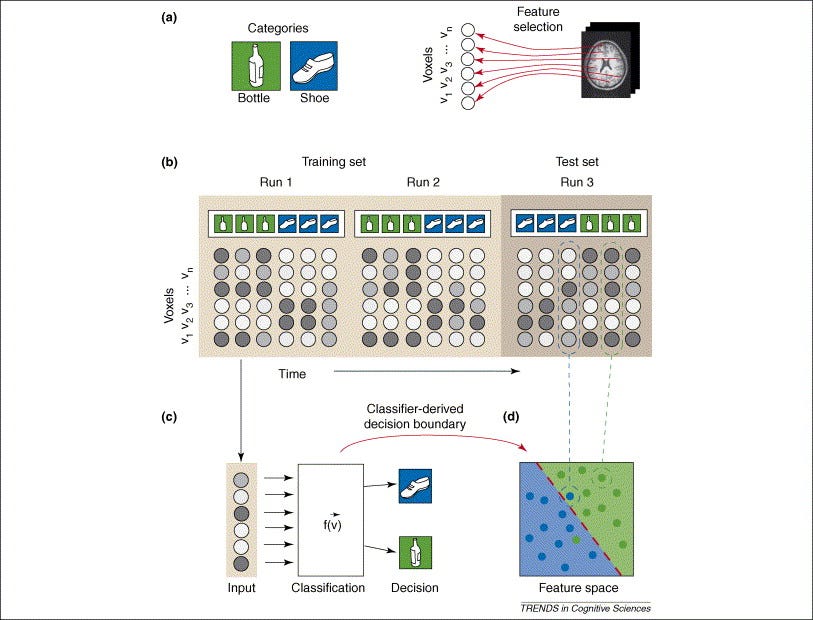
(a.) The two cognitive activities involve seeing a bottle or seeing a shoe. Then, feature selection picks voxels that are relevant in our analysis. (b.) Brain patterns are grouped and labeled. (c.) We then train our classifier based on the grouped and labeled data. (d.) We run our trained classifier on our test set. To better understand how to interpret the blue dots divided into two groups, look into SVM Classifiers, or look below at the section titled Classification Algorithms 6
In case the preceeding section did not make sense, we take a brief digression into classification as a principle, and discuss how this facet of machine learning operates in general.
Classification Algorithms
The actual classification algorithm used in performing a multi-voxel pattern classification is not as important, as the classification has been performed with a plethora of different classification algorithms, ranging from Support Vector Machines to Gaussian Naive Bayes classifiers.
A brief description of one such classifier, a Support Vector Machine (SVM), is described below for those unfamiliar.
Quick Refresher on SVM Algorithms
💡 If you have never seen such an algorithm before, this section is likely confusing. I suggest you either (1) read up on SVM algorithms or (2) skip this section and carry on knowing simply that a classifier is an algorithm that classifies unlabeled data based on a model already trained on similar, labeled data.
An SVM is an incredibly popular supervised machine learning algorithm used for classification problems. Simply put, an SVM learns to classify data by placing data points on a plane, and spliting them so that points on one side of the boundary are classified one way, and points on the other side are classified the other way. When it’s time to classify a new, unseen data point, it is placed in its relevant position on the plane—based on its unique features—and classified according to what side of the boundary it rests on. Remember that in this case, the classification is the cognitive state and the data points are fMRI scans. Please note that this explanation is incredibly simplified, and serves only to provide beginners with a brief, high-level understanding of SVMs. For a more detailed understanding of the algorithm, see here.
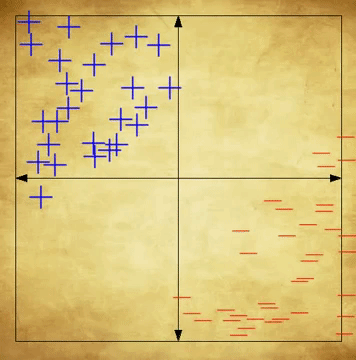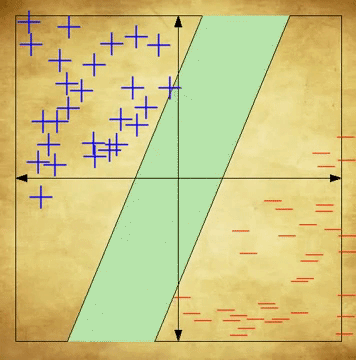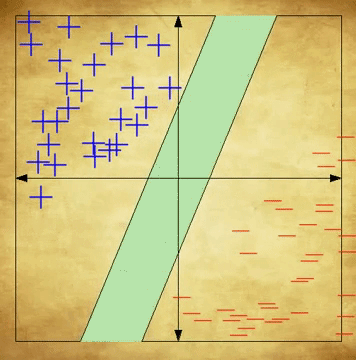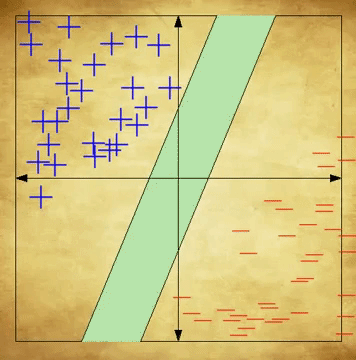
The above gif shows the hyperplane of a data set, and the construction of an “optimal boundary” between possible outputs. 7
Classification Analysis: Limitations & Implications
The preceding discussion begs the question, what conditions would produce the ideal classification? Practically, it would be easiest to classify a cognitive state given that it is very distinguishable from other cognitive states. In other words, if certain geographic locations—far apart from each other—in the brain “light up” only during certain distinguishable tasks, the cognitive state is easily classifiable. Thus, the geographic distance between neurological activation is incredibly relevant in determining the accuracy of our classification.
Some cognitive states are more easily classifiable, because they light up distinct regions of the brain far from each other. Examples include seeing a face (which tends to light up the fusiform face area of the brain), looking at a house (which tends to light up the parahippocampal place area of the brain), or lifting one’s left or right thumb (each lighting up different parts of the brain as well). The differences in signals coming out of the two geographically distinct regions mentioned above are described better below:
Here, the distinction in brain signals produced by either perceiving a house or face are emphasized. The peaks with arrows are areas where the participant was likely viewing a house or face. It’s that simple! 4
Thus, scientists can often classify exactly what type of object an individual is looking at, simply by looking at what region of their brain is most active. In context of a Machine Learning classifier, this means we can build a more confident decision boundary, with a clear distinction between classification labels.
Limitations
Although some cognitive states allow for simple classification, others may have overlapping patterns that are difficult to distinguish. For a more accurate classification, analyzing the brain at a lower spatial scale—or zooming in—may decode more subtle patterns. By doing so, we can analyze the smaller regions of the brain more precisely, contributing to a more detailed analysis overall.
✔️ “Strikingly, despite the relatively low spatial resolution of conventional fMRI, the decoding of image orientation is possible with high accuracy. Prediction accuracy can reach 80%, even when only a single brain volume (collected in under 2 seconds) is classified.”4
Dynamic Stimuli
💡 Dynamic Stimuli is a broad term to used to describe a cognitive state that encapsulates a “continually changing stream of conciousness”4. In essence, any mental process that sparks complex, multifaceted thought or experience can be considered dynamic.
Thus far, the previous examples discussed only cover an individual static stimulus, like imagining a single house or face for a prolonged period of time. But what if the cognitive processes we aim to classify involve multiple, dynamic stimuli, such as moving one’s eyes around amidst a natural viewing condition?
Imagine trying to classify what an individual cognitive state while looking around in this view. This would be a tough problem.
This, unfortunately, proves to be a severe limitation in neuroimage classification—there is simply too much being perceived at once, and too many cognitive states to potentially overlap. Dynamic stimuli also happens to be more common, as we typically do not focus on individual, static stimuli for prolonged periods of time outside of experimental conditions.
Although classifying such complex stimuli is a more difficult task, it has been done in a rudimentary way before. Scientists have, in the past, analyzed brain activity of participants watching movies by successfully identifying when faces, buildings, and action items were perceived.4 Beyond that, however, the technology simply hasn’t caught up to being able to comprehensively decode a dynamic state accurately.
Data Quantity
Another limitation of such classification involves finding enough labeled data for the model. Accurately training a classifier requires access to a plethora of fMRI data with labels corresponding to the respective cognitive state. This can be tedious to develop and difficult to find. One solution to such a limitation is data augmentation, which is a strategy that allows one to produce modified copies of existing data to increase the quantity of overall data. To read more about a specific augmentation architecture for biomedical data like fMRI scans, see this paper.
Further Limitations
Although the preceding classification methods and results paint a starry picture of the potential of mind reading, there are more limitations necessary to discuss. One such limitation is that of limited training labels. We can only train our classification model on so many labels of data, but how can we ever encapsulate the infinite cognitive states in our model? Sure, we can train a classifier to recognize when an individual sees a house or a face, but what about when an individual contemplates the meaning of life? How can we possibly train a model to cover every possible thought?
Besides for this limitation, there are a plethora of others. As of now, neuroimaging methods for classification…4
Are expensive and difficult to practically employ
Rely on processing brain signals that are still not well understood
Struggle to generalize to real-world situations, as there are so many cognitive processes occurring at once in day-to-day life (See above, Dynamic Stimuli). This also leads to an overlapping effect, where two mental states at once may interfere with each other, making it difficult to distinguish what is being experienced.
Fail to contextualize mental states
For example, if one enacts the same cognitive process (like seeing a house), at two different times and in two different mental states (like feeling upset or happy), the brain signals given off may vary, contributing to an inaccurate classification. The solution, of course, is then to generalize our classification algorithm to be applicable in a plethora of mental states. However, doing so comes at the cost of a less distinct, accurate model.
Vary across individuals. This is an incredibly severe limitation of such a device. As we are all shaped by our own, unique experiences, it is difficult to build one device that can classify the same cognitive state in multiple people. As such, a model trained on labeled cognitive states of one person may not extend to the complex cognitive states of another.
Come with ethical concerns, which are further discussed in the next section.
Implications
Potential Beyond Consciousness 🧠
📖 Merriam Webster defines consciousness as “the quality or state of being aware especially of something within oneself”8
Thus far, we have only discussed the classification of conscious thought, such as visual stimuli. Unconscious mental states are special because the individual encapsulating such thoughts is unaware of them. Thus, classifying these thoughts may allow an individual to learn more about their subconscious state of mind, possibly helping reveal underlying sources of stress or other emotion. Or, more significantly, underlying biases or predispositions may be uncovered through such classification. https://en.wiktionary.org/wiki/tip_of_the_iceberg Imagine trying to classify what an individual cognitive state while looking at the above picture. This would be a tough problem.
In fact, there are a plethora of papers that have uncovered subconscious racial biases through the very neurological classification techniques described above. One such study11 uncovered that when presenting white participants with black and white faces, “activation in the amygdala-a brain region associated with emotion-was greater for black than for white faces.” Thus, an individual’s unique racial biases literally impact the way our brains light up. What if we could classify people’s biases? This truly introduces a whole new field—a little beyond the scope of this post—existing at the intersection of racial relations, machine learning, and neuroscience. If you would like to delve deeper into subconscious neurological classification, see a few of these studies.8,9,11
The implications of subconscious classification are truly endless. Imagine being able to prevent a potentially dangerous, subconscious motor movement from occurring? Or being able to warn an individual, and their loved ones, of a dangerous subconscious thought they experience. Learning to fully comprehend our subconscious allows us to finally possess the key to the depths of our consciousness, a lock that has been sealed tight since the start of humanity.
However, possessing this key comes with great responsibility. As such, a misuse of such a power can prove to be an incredibly dangerous ethical concern.
The Ethical Basis
Identifying information of the mind, such as hidden racial biases, can be controversial, and potentially pose a privacy concern. Classifying brain imaging data in such a way may reveal private information like “emotional states and attempts at their self-regulation, personality traits, psychiatric diseases, criminal tendencies, drug abuse, product preferences, and even decisions.”4
Of course, as outlined in our discussion of the limitations of this technology, neuroimaging-based classification is simply not advanced enough for this really to be a concern. However, advancements in this field have been exponential, with new findings coming out everyday. As such, it’s essential to be wary of how this comes into play from a moral perspective.
This concept of the “privacy of the human mind” is well discussed in Neuroethics: the practical and the philosophical12. The paper outlines the unique invasions of privacy that come with brain imaging, such as neuromarketing, a way to “measure limbic system response to a product that may indicate consumers’ desire for it.” Other risks include brainotyping, which involves revealing mental health vulnerabilities in people, which can then be easily taken advantage of. Sexual attraction can also be discovered through neuroimaging, which can further be used as a means of emotional manipulation. Again, this shouldn’t be a concern in the present, considering our current technological advancements simply aren’t advanced enough. However, some experiments completed have already been able to uncover private personality traits of individuals.
One such example is an experiment that discovered “extroversion was correlated with amygdala response to pleasant stimuli, using photographs of puppies, ice cream, sunsets and so on.”. Here, scientists find a clear way to gauge how extroverted a person is, just by looking at their brain scan data. 13
⚠️ Can you see how being able to find the “extroversion score” of an individual can be dangerous? Imagine if companies began altering their recruiting priorities to conform to such scores, extrapolated directly from the brains of their candidates? Being able to extrapolate a personality score directly from brain scan data is a controversial topic. Where would you draw the line?
A poster from the dystopian novel, Nineteen Eighty-Four, in which the thought police regulate even what you think. Could Big Brother be using Support Vector Machines to watch you? 13
What’s interesting about neuroethics is that it can be difficult not to violate the privacy of the human mind. Each brain scan includes multiple voxels (see above, Methods of Multi-Voxel Pattern Classification), each containing unique information about the individual’s mental state. Thus, the same series of brain scans may encapsulate a multifaceted log of the user’s mental state. So, even if the brain scan is used ethically for a consensual, scientific analysis, the brain imaging data can always be leaked and interpreted against one of its other facets for unethical, non consensual cognitive states. Thus, because the same scan may encapsulate multiple cognitive states, there exist drastic ramifications if the wrong hands gain access to such data.
At the same time, when used responsibly, such classification methods have huge potential—from predicting brain diseases to unlocking hidden, subconscious memories. Perhaps the most marvelous implication of such classification is its ability to complement the field of neuroscience—allowing us to learn more about the brain as a whole. This idea—of neuroscience and Machine Learning complementing each other—is what I refer to as the perpetual cycle of progress.
The Perpetual Cycle of Progress
A side-by-side, simplified comparison of a biological neuron and an “artificial” neuron as used in Artificial Neural Networks (covered next). This comparison introduces the Perpetual Cycle of Progress, a term I use to describe the complementary nature of neuroscience and AI. 18
In this section, we discuss the magnificent complementary nature of neuroscience and Artificial Intelligence. Before doing so, however, we must touch on Artificial Neural Networks.
ANN’s
Preceding this section, we have only described traditional ML approaches for classification, such as SVMs. For more advanced classification tasks, we may use Artificial Neural Networks (ANN) that serve the same purpose of classification, but differ in their use of neural networks. Neural networks can be thought of as a series of algorithms “modeled loosly on the human brain.”18 A comprehensive understanding of neural network is out of scope of this blog post, but for a surface-level understanding, read the following optional blurb.
📖 Optional Refresher on Artificial Neural Networks A neural network contains a plethora of interconnected nodes with corresponding weights (numbers). The nodes are organized into layers, and process data from previous layers by summing up different values based to their weights, only letting certain data pass based on a threshold. To train a neural network, the weights are initially set to random values, and training data is inputted into the bottom layer. The training data traverses—layer by layer—through the network, getting manipulated by the various weights and thresholds, until it arrives at the output layer. Comparing the results of the output with the actual labels of the training data, the weights and thresholds are adjusted until the network produces accurate classifications. This explanation, however, does not do justice to the beauty of neural networks justice. For a better introduction, see this playlist. Otherwise, for the sake of this blog, simply understand that neural networks are roughly analogous to the human brain’s own neurological connections. To better drill in this analogous nature, note that “particular network layouts…weights, and thresholds have reproduced observed features of human neuroanatomy and cognition, an indication that they capture something about how the brain processes information.” 18
The Perpetual Cycle
Thus far, we’ve seen that classification algorithms may allow us to identify patterns between fMRI scans and cognitive processes. In doing so, they contribute to a deeper understanding of the brain as a whole. What’s even more interesting, however, is the dual-sided nature of this concept.
In the same way we can use AI to learn about the brain, we can also use the brain to learn about AI. Because Artificial Neural Networks are roughly modeled around biological neural networks, a detailed observation of a real, palpable human brain may lead to new ideas in the sphere of AI. In essence, “the human brain could be thought of as a computing device,” 18 one that we can take inspiration from in our construction of other computational devices.
Considering the dual-sided nature of this phenomenon, we can conclude that the two fields act symbiotically, mutually reinforcing each other by forming new discoveries about the other. Researcher Chethan Pandarinath of Emory University describes this phenomenon well, pushing that “the technology is coming full circle and being applied back to understand the brain”19.
“If you can train a neural network to do it, then perhaps you can understand how that network functions, and then use that to understand the biological data.”19 David Sussillo, from Google Brain.
An example of the situation Sussillo describes above can be seen through the work of two researchers from Stanford University, who were able to build an accurate ANN to recognize objects. After comparing their ANN to the actual, biological brain of a monkey, they “were able to match areas of their network to areas of the brain with about 70% accuracy.” 19 In essence, the researchers were able to build a model similar to an actual, biological brain—one that can now serve to help demystify a previously convoluted cognitive process—in this case, object recognition, which is a “poorly understood” cognitive process in the field of neuroscience. Examples like these are no rare occurrence, and discoveries in both neuroscience and AI propel the other forward.
Conclusion
The human brain can solve nearly any problem. And so it is particularly ironic that the brain remains such a mystery to itself. We understand the broad structures of the brain—we know what the pieces are and, to some extent, what they are capable. But we have yet to truly understand how it operates.
We’ve seen, however, that through neuroimaging-based classification, we can—roughly—“read minds”. More accurately, using Machine Learning, we can draw informed classifications of cognitive states directly from brain imaging data.
As such, research in the field has incredible implications, like being able to predict neurodegenrative diseases—like Alzheimer’s—before they strike. Such possibilities make it clear that by leveraging technology that mimics the brain, we can learn to save it.
This approach is arguably more comprehensive than those taken in the past with non-ML BCI’s, although it still has its limitations. The most drastic limitation, perhaps, being the ethical concerns that come with extracting potentially sensitive data from fMRI scans.
Despite these concerns, the intersection of neuroscience and AI allows for a breathtaking phenomenon of mutual reinforcement, with the two fields complementing each other in a perpetual cycle of progress. The more we learn about the brain, the better our AI systems become. The better our AI systems become, the more we learn about the brain. This perpetual cycle of progress is beautiful, and allows us to make incredible steps towards teaching the brain to discover itself.
(https://www.theguardian.com/science/blog/2012/feb/28/how-many-neurons-human-brain)
(https://www.sciencedirect.com/science/article/pii/S1364661306001847)
(https://www.sciencedirect.com/science/article/pii/S1364661304002955)
(https://link.springer.com/article/10.1007%2Fs13244-016-0534-1)
(https://news.mit.edu/2017/explained-neural-networks-deep-learning-0414)
(https://www.digitaltrends.com/cool-tech/what-is-an-artificial-neural-network/)