
Neural Module Networks for Visual Question Answering

by Andre He
In this blog post, we will explore how the authors of Deep Compositional Question Answering with Neural Module Networks use a modular architecture to handle the task of visual question answering. We will first introduce the VQA dataset and discuss some insights about the task, before diving into the design of neural module networks.
What is Visual Question Answering and why it matters
Language can describe various objects, attributes, and relationships that we use to see the world. Our understanding of language is largely grounded in our experience with these objects, in which visual experiences are particularly rich.
For example, when taught “this is one red apple” as they are shown such an object, children can potentially gain information about not just the appearance of an apple, but also what it means to be red and count one thing.
Once basic associations are established between phrases and objects, one can even learn features of the language that are not visual in nature, such as semantic relationships. Continuing the example, a more deliberate comment like “this is an apple, and it is red” might teach the child about the semantic functions of the logical “and” and the pronoun “it”. Of course, many examples and counterexamples would be needed, but this suggests the possibility of learning some language features (not necessarily visual!) from labelled images rather than text.
Motivated by the semantic richness of images, visual question answering is a task that is not only useful by itself, but also opens a way for computers to learn language visually. The Visual Question Answering dataset contains open-ended questions about corresponding images, which require an understanding of vision and language to answer correctly.

Image 1
Q: Did he just hit the ball?
Q: Is the boy in front of the fence?
Q: What sport is this?
Image 2
Q: Are there napkins on the table?
Q: Has any of the food been eaten?
Q: What pastries are offered?
Image 3
Q: Is this surf what a surf-boarder wants?
Q: What is in the background of the photo?
Q: Where is there any haze in this photo?As you can see in the examples above, the questions require us to process various objects (ball, fence, table, etc.) and relationships (in front, on, in the background, etc.).
Reasoning About Composed Questions
Neural module networks are specially designed to handle the compositional structure of questions. Before we get into the architecture, let us understand what is meant by “composition” in VQA through an example. Suppose we want to answer “Are there two dogs touching a food dish with their face” about the following image.

As humans, we would take many intermediate steps before arriving at a conclusion – we need to find the dogs first, locate their faces, identify contact with the food dish, then count whether there are two such cases. It is hard to imagine a model that can reliably answer such a question without implicitly or explicitly decomposing them. In this sense, the question is composed from atomic questions like “where is the dog”, “where is X’s face”, or “are there two of X”.
To specifically test the NMN on compositional questions, the authors synthesize a SHAPES dataset. Like VQA, SHAPES also contains questions about images, but these images consist only of abstract shapes in a 3 by 3 grid. The vision component of this dataset is almost trivial, so it serves to demonstrate the NMN’s ability to understand questions. The examples below also give a good idea of the type of question a NMN is designed to handle.

Q: Is there a red shape above a circle?
Q: Is a red shape blue?
Q: Is there a circle next to a square?
Q: How many triangles are there?Neural Module Networks
Let’s get to neural module networks themselves. In a nutshell, we want to build a collection of neural networks that are each trained to perform an atomic task. These will be our “modules”.
Remember how we decomposed questions into atomic sub-questions? On a very abstract level, each module handles a class of these atomic questions. For example, one module can be trained to find a given token, such as “dog”, in the image. It answers questions in the form “where is X”. To answer, say “is A touching B” or “how many X are there”, we would need different modules.
Clearly, these modules would need to pass information around to handle composed questions. A “counting” module needs to know where a “find” module found dogs to count them. Modules need to output some representation of their answer to their part of the question, and attention maps turn out to be a convenient one.
An attention map is a single-channel image of the same size as the input image. We intend for the modules to use these maps as a way to highlight relevant parts of the image. When modules have objects (dog) or an area (around dog, next to dog, etc.) as answer, the corresponding region should be assigned higher pixel values.
For VQA, authors of the NMN paper chose attention, re-attention, combination, classification, and measurement as the modules. On a high level,
attend finds simple objects in the image;
re-attend and combine compose objects into higher level ones;
and classify and measure look at the selected object to answer the question.
Attention
The attention module takes as input an image and outputs an attention map. The module is also conditioned on a word token representing the object that it should attend to. It is implemented with convolution layers. This is basically the “find” module described above.
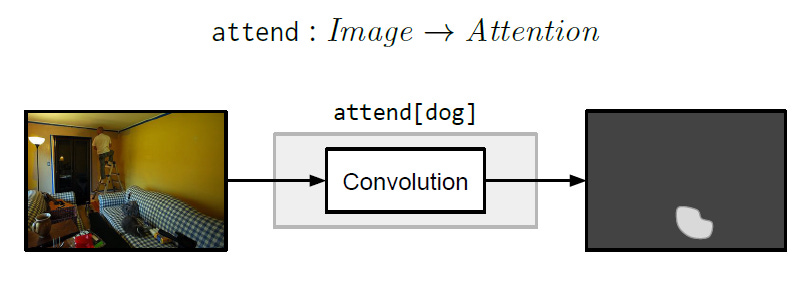
Re-Attention
The re-attention module acts on an attention map, conditioned on a spatial or logical relationship. For example, re-attend[above] shifts the attention upwards, whereas re-attend[not] inverts the attention on regions. It is implemented with a multilayer perceptron.
Combination
The combine module combines two attention maps according to a logical relationship. For example, combine[and] outputs the union of two attention maps, whereas combine[except] attends to regions that are active in the first map and inactive in the second map.
Classification
The classify module takes an image and attention map and outputs a distribution over labels. It is conditioned on a word token representing what property to classify. For example, classify[color] should output a distribution over color labels.
The classification is done by a fully connected layer plus softmax on the element-wise product between the image and attention map. This motivates the modules to actually use attention maps as intended, selecting relevant objects and masking out irrelevant regions.
Measurement
The measure module is similar to classification in that it outputs a distribution over labels, but it only looks at the attention map. It is suitable for counting or testing existence. Counting is done as a classification over integer labels.
Now that the modules are defined, let’s look at another example. This figure from the paper shows how the question “is there a red shape above a circle?” can be answered by evaluating
measure[is](combine[and](re-attend[above](attend[circle]()),attend[red]()))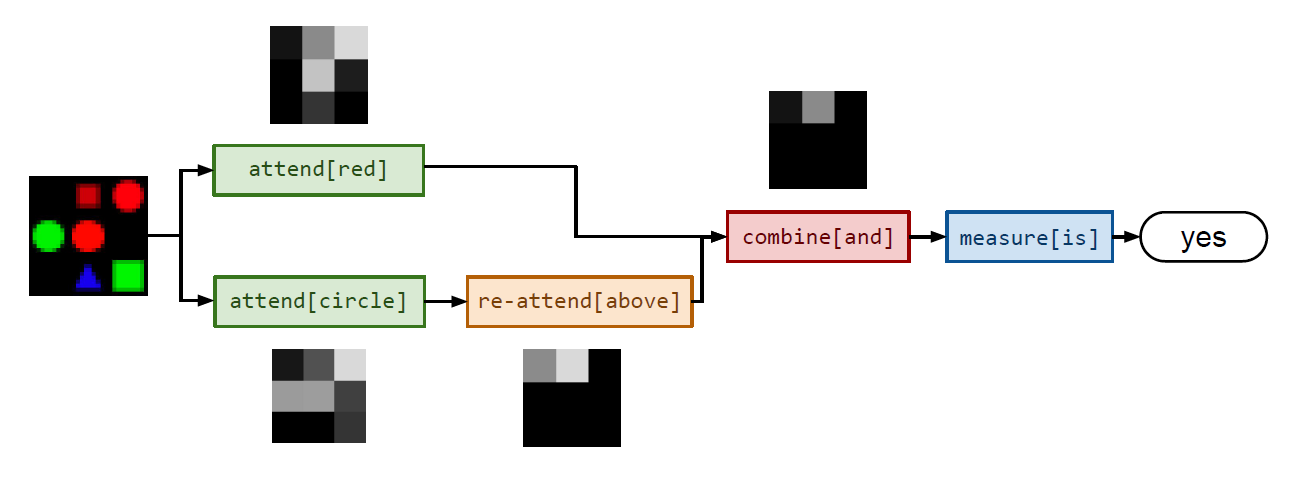
Composing these function calls can also be thought of as assembling the modules into a larger network, analogous to how repeatedly applying a RNN unit is represented as a chain-like architecture. It is helpful to picture it this way, since there will be gradients flowing end-to-end through this assembled network during training, which we will discuss later.
Layout
So far, we have seen the intended function of each module, and that it is possible to answer composed questions by building the correct function call. There remains one problem: how would the model know how to assemble the network?
We can make the reasonable assumption that module layout should only be a function of the question. Imagine doing VQA yourself — the question should guide you to look for the same objects and relationships even if the image is substituted.
Naively, we might try to design a function that translates the question’s syntax tree into a module layout. This seems quite feasible at first, since phrases combine similarly to how the modules should combine, but it fails when there are more complex dependencies within the question.
Fortunately, we have the off-the-shelf Stanford Parser that captures dependencies, such as that between objects and their attributes, or wh-words and their subjects. In contrast to syntax parsers that only compose adjacent words, the dependency parser can handle references and relationships across parts of the sentence. Below is the output of the parser on two questions from VQA and one from SHAPES.
What color is the truck ?
det(color, what)
obj(be, color)
root(ROOT-0, be)
det(truck, the)
nsubj(be, truck)
What is standing in the field?
nsubj(stand, what)
aux(stand, be)
root(ROOT-0, stand)
case(field, in)
det(field, the)
obl:on(stand, field)
Is there a circle next to a square ?
root(ROOT-0, be)
expl(be, there)
det(circle, a)
obl:npmod(next, circle)
advmod(be, next)
case(square, to)
det(square, a)
obl:to(be, square)For this task, we filter the set of dependencies connected to the wh-word (i.e. what, when, is, how many, etc.). This gives a symbolic form of the primary object in question and what is asked about it. Other preprocessing steps like lemmatization and determiner removal are involved, but we won’t go into detail here.
what is standing in the field -> what(stand)
what color is the truck -> color(truck)
is there a circle next to a square -> is(circle, next-to(square))The final step is to translate these filtered dependency trees to module layouts. All leaves become attend modules, internal nodes become combine or re-attend modules (depending on the number of inputs), and root nodes become measure or classify nodes (depending on the question type: existence/counting or classification).
Intuitively, leaves attend to objects in the image, intermediate nodes combine and process them according to semantic relationships, and finally the root node outputs a probability distribution over answers.
The authors found it helpful to have a LSTM read the question and add its output to the root module’s output before producing the final label distribution. This helps model common sense knowledge and dataset biases. For example, it is reasonable to guess that a tree is green when the model can’t find it in the image.
Training
At this point, we have described all the components necessary for a forward-pass of the neural module network. It can be trained with the same backpropagation-based optimizers as our usual monolithic networks.
Given a training sample (w, x, y), where w is the question, x is the image, and y is the ground truth answer, the model parses a layout from w and runs x through the assembled network. The loss is computed on the model output y′ and target y. Gradients then flow back through the assembled network, tuning parameters in each module, as if it was a single network.
Results
SHAPES
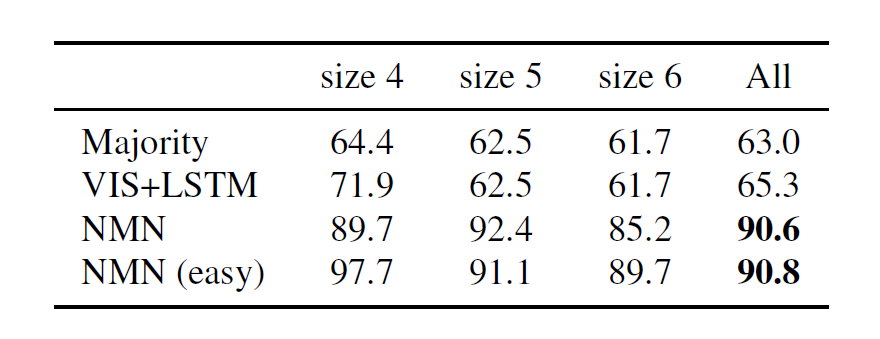
On the toy SHAPES dataset, NMN outperforms a baseline from previous work and demonstrates some degree of compositional generalization. Here NMN(easy) is a model that never sees questions requiring 6 or more modules during training. It still achieves high accuracy on size 6 test questions.
VQA
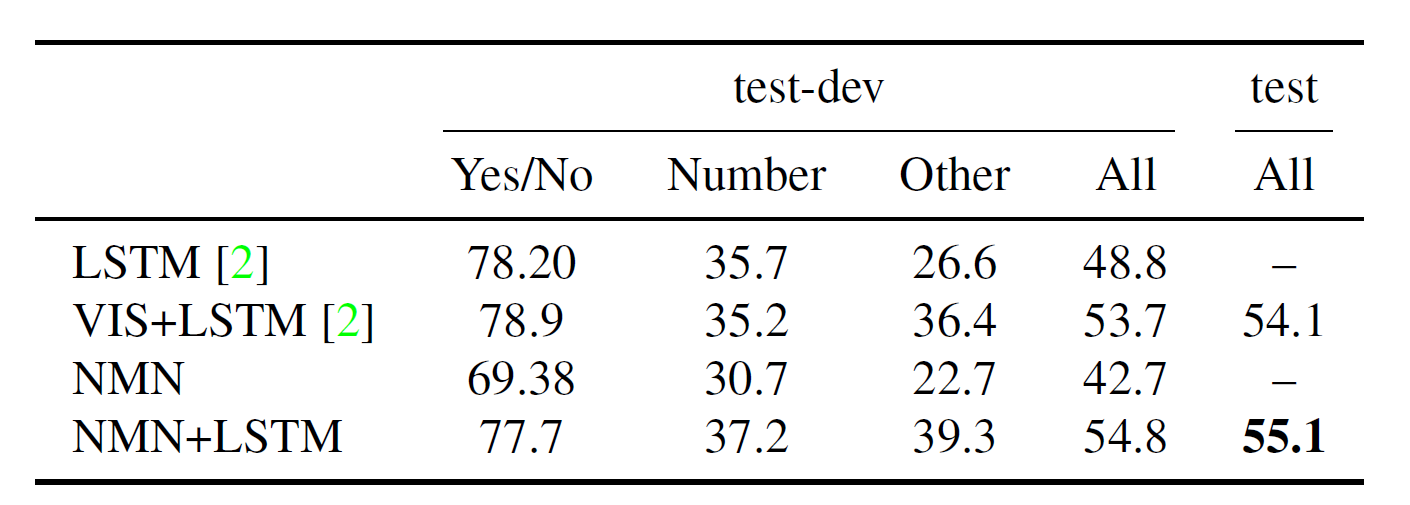
The full model (with LSTM) outperforms previous approaches on VQA. However, it does noticeably poorly on counting tasks, probably because it is difficult for the single-layer measure module to express a counting function.
Later Work
We will briefly go over some later work on NMNs.
Learning Layouts
It is a natural question to ask whether NMNs can bypass the need for a “hardcoded” layout parser and jointly learn modules and a layout builder in an end-to-end fashion. In Learning to Reason: End-to-End Module Networks for Visual Question Answering, the authors jointly train a RL layout policy with the modules.
The REINFORCE-based layout policy learns from a reward indicating whether its predicted layout, using current parameters for the modules, outputs an answer distribution close to the ground truth. The intuition is that the layout policy can try different ways to assemble the modules and learn from whether they give reasonable outputs.
An optimistic observation is that the NMN with learned layout policy may no longer need human-defined modules. In theory, it should be able to learn modules from scratch to perform whatever functions it finds necessary. However, the joint training turned out to be very difficult in practice, and the authors resorted to pre-defined and pre-trained modules similar to the ones listed above.
Faithfulness
In Obtaining Faithful Interpretations from Compositional Neural Networks, it was shown that NMNs trained only on end-task supervision produced uninterpretable module outputs. In other words, the modules were not faithful to their intended functions.
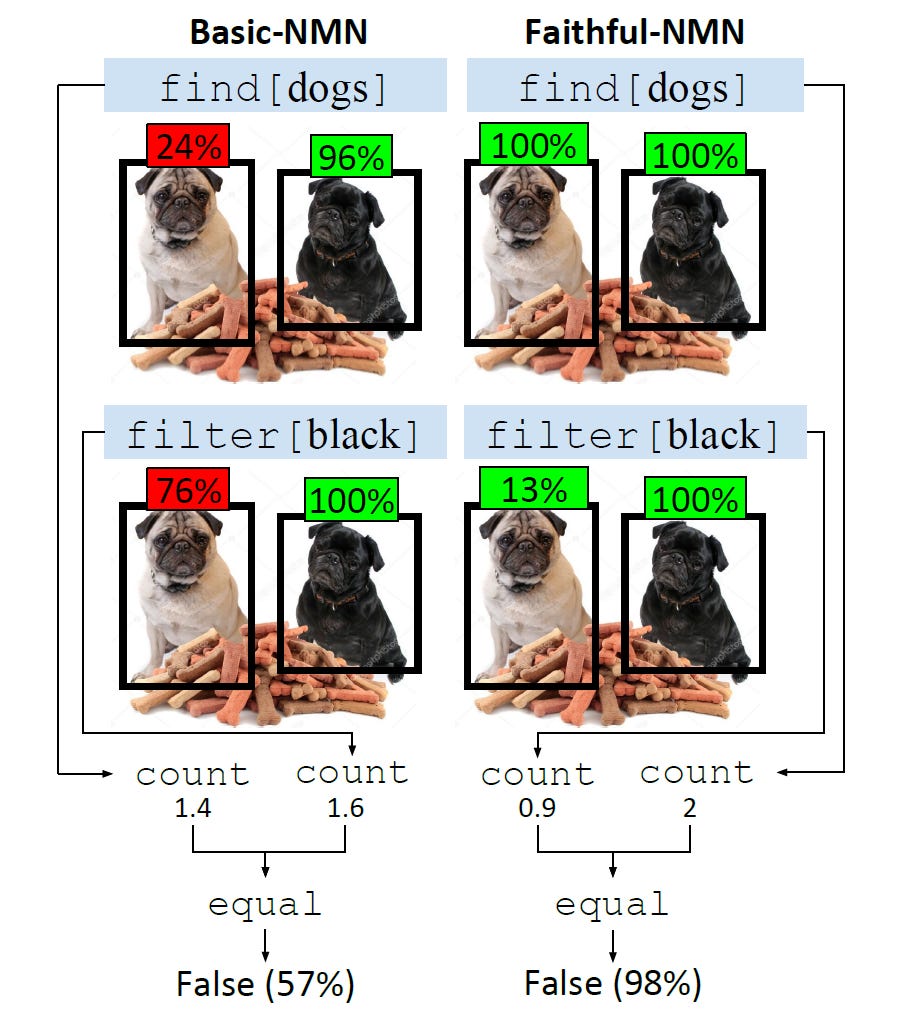
In some versions of NMNs, the modules have access to contextualized embeddings, which carry information about all words in the question, as opposed to just the word corresponding to that module. They also have different modules, e.g. find and filter.
The authors suggest that some reasoning steps (filter) were collapsed into other modules (find) frequently found together. Faithfulness was improved by supervising intermediate modules on gold module outputs, limiting module expressiveness, and decontextualizing word embeddings. This improved generalization on the text QA task, though it is unclear whether it did the same for VQA.
References
Neural Module Networks https://arxiv.org/abs/1511.02799
Learning to Reason: End-to-End Module Networks for Visual Question Answering https://arxiv.org/abs/1704.05526
Obtaining Faithful Interpretations from Compositional Neural Networks https://arxiv.org/pdf/2005.00724.pdf