
Generalized Neurons

By Max Smolin
The Universal Approximation Theorem is a fundamental result in the mathematics of deep neural networks. It states that using any continuous activation function (other than a polynomial), a neural network of some sufficient width (layer size) and at least one layer can approximate any given continuous function arbitrarily closely.
")
This theorem is important because it places neural networks in the elite club of models that can “do anything” given enough space and time.
The caveat, of course, is that enough may not be physically possible.

Indeed, in practice we work with neural networks of very limited width and with extremely limited computational capacity. Moreover, many activation functions that we use in practice are not continuous (most importantly, ReLU). So how does the UAT translate to the real world?
Examining Neurons
Ultimately, the simplest neural network is a single neuron. Let’s examine a neuron’s representation capacity before building up to layers and deep networks.
As a reminder, a traditional artificial neuron is simply a construct that first takes a linear combination of its inputs and then feeds it through a non-linear activation function.
def artificial_neuron(input):
kx = weights * input # element-wise product
linear_combination = kx # no bias for simplicty
return phi(linear_combination)For simplicity we will assume that the activation function is ReLU, so
Under this assumption, the range (possible outputs) of this neuron will be limited by the ReLU to [0,∞).
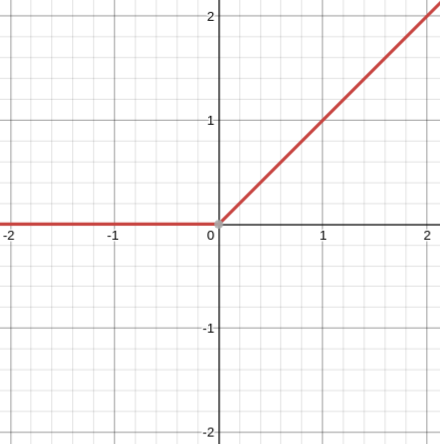
We can annotate the neuron’s code to see how the possible data values change:
def artificial_neuron(input):
# input ∈ (-∞, ∞)
# weights ∈ (-∞, ∞)
# bias ∈ (-∞, ∞)
kx = weights * input # ∈ (-∞, ∞)
linear_combination = kx # ∈ (-∞, ∞)
return phi(linear_combination) # ∈ [0, ∞)Two Neurons
Now let’s examine what happens when we stack two neurons:
def artificial_neuron_2(neuron_1_output):
# neuron_1_output ∈ [0, ∞)
# weights2 ∈ (-∞, ∞)
# bias2 ∈ (-∞, ∞)
kx = weights2 * neuron_1_output # ∈ (-∞, ∞)
linear_combination = kx # ∈ (-∞, ∞)
return phi(linear_combination) # ∈ [0, ∞)
def network(input):
x = input # ∈ (-∞, ∞)
x = artificial_neuron(x) # ∈ [0, ∞)
x = artificial_neuron_2(x) # ∈ [0, ∞)
return x # ∈ [0, ∞)We can see that stacking neurons does not change their output range since the stack always ends in a ReLU.
This might cause concern since neural networks are able to learn negative outputs but we just specified that their output is always ≥0 regardless of the depth!
The solution that is used in practice is to add a neuron without an activation function at the end of the network to convert its range back to (−∞,∞):
def network(input):
x = input # ∈ (-∞, ∞)
x = artificial_neuron(x) # ∈ [0, ∞)
x = artificial_neuron_2(x) # ∈ [0, ∞)
x = weights_end * x
return x # ∈ (-∞, ∞)Family of Functions
Clearly our primitive neural network is able to express functions over the range of all reals. But are there any restrictions other than range on the family of functions that it can approximate? The answer, trivially, is yes.
The narrow network that we considered before (just a stack of ReLU neurons) is, for example, unable to represent f(x)=x:
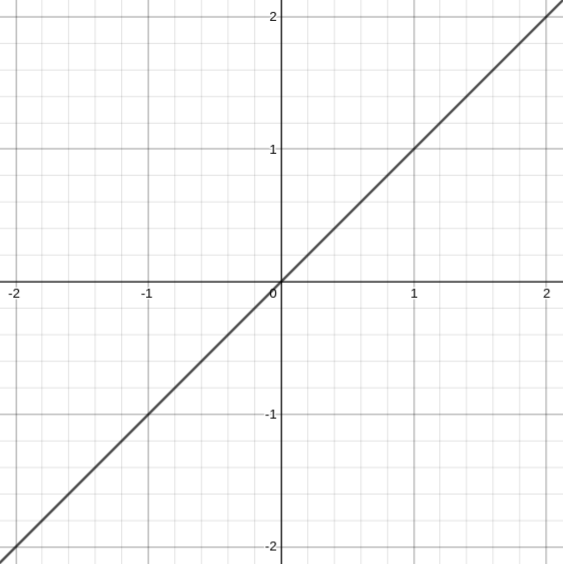
This is because our network’s output is either all ≥0 or ≤0, even given the final non-activated layer! A negative weight at the end takes [0,∞) to (−∞,0] and a positive weight leaves it the same:
def network(input):
x = input # ∈ (-∞, ∞)
x = artificial_neuron(x) # ∈ [0, ∞)
x = artificial_neuron_2(x) # ∈ [0, ∞)
x = weights_end * x
if weights_end < 0:
return x # ∈ (-∞, 0]
elif weights_end > 0:
return x # ∈ [0, ∞)
else
return 0Note that this is completely not an issue for a network that is at least two neurons wide:
The above definition is an example neural network that produces the desired function:
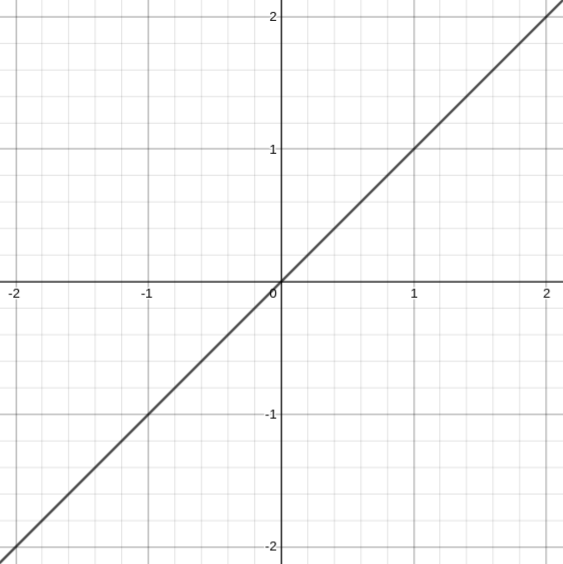
Sidenote: This is why infinite width is a condition for the UAT.
Approximating on an Interval
Before we move on from the identity function, look at this graph of a different, 1-wide neural network:
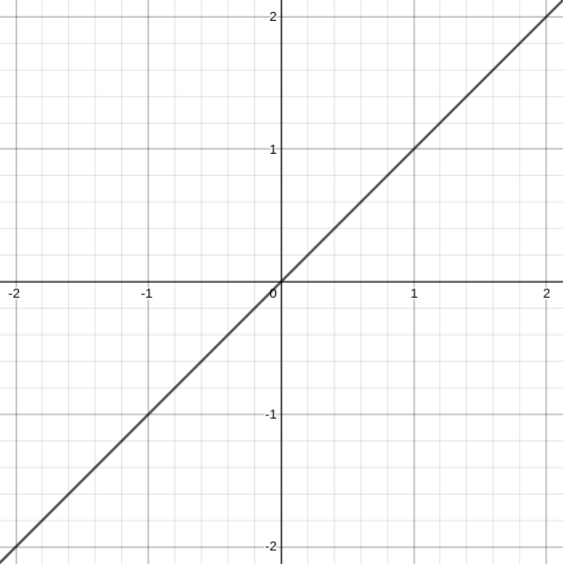
This network perfectly expresses the identity according to the graph. Didn’t we just determine that this was impossible? That no 1-wide neural network could express the identity? Well, yes, here is the above graph but zoomed out a bit:
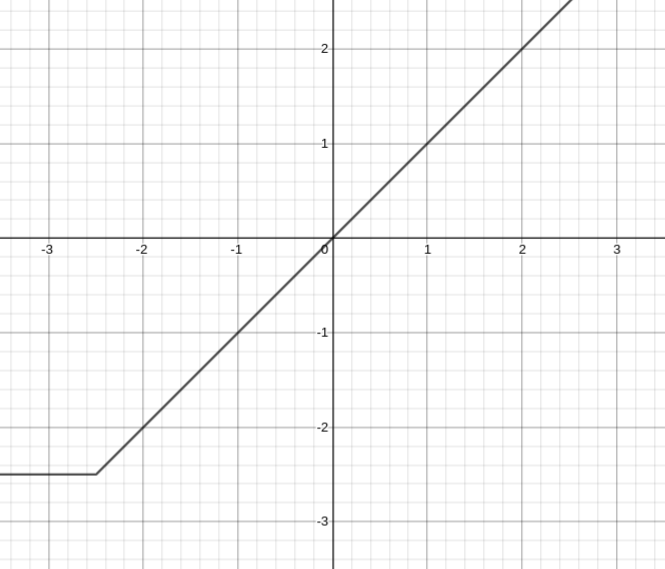
Turns out this is clearly not the identity function.
But, there is an extremely important takeaway here---neural networks can approximate functions on an interval with us fully believing that the approximation is general.
This point is made so much more crucial by the fact that modern networks universally include normalization layers which constrain the values that the network operates on to small intervals.
Additionally, in practice, constraining learning to intervals is necessary to quickly and efficiently train a deep neural network.
The question is---does this constraint have any unintended side-effects?
Multiplication
We will stop our general analysis of neural network expressive power there and think instead about a simple example. Can a neural network learn f(a,b)=a×b?

The answer is YES:
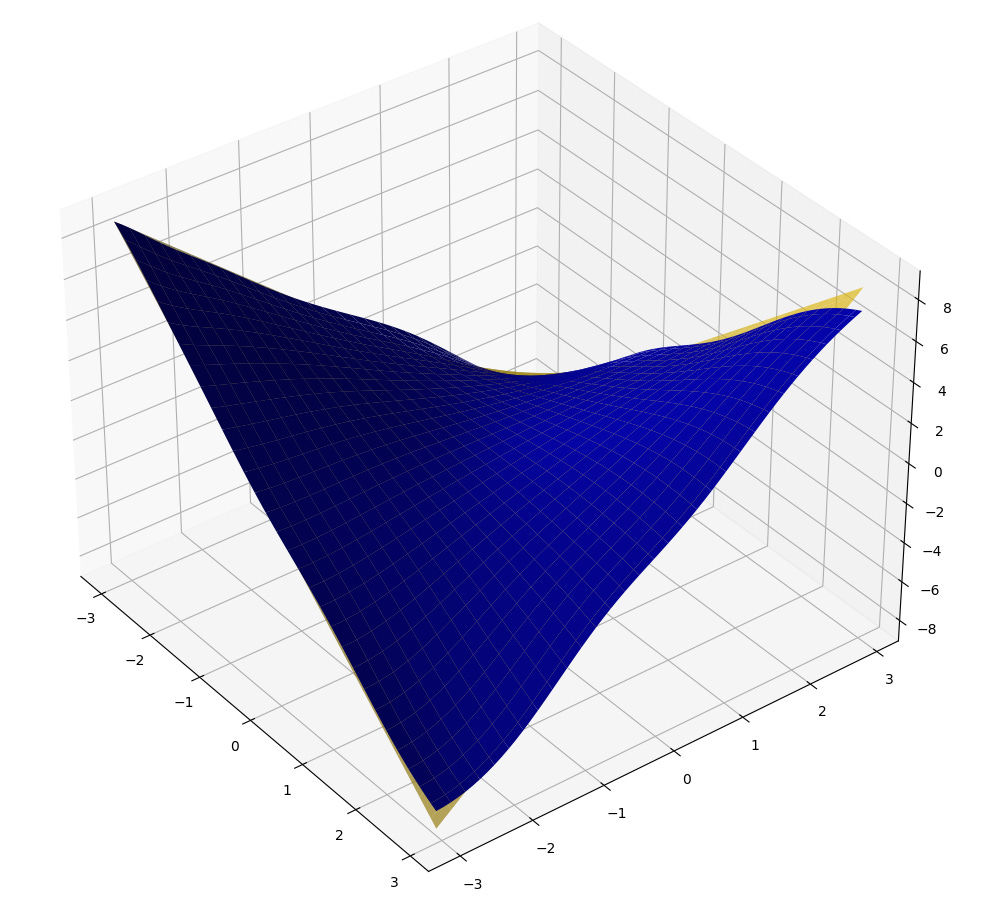
(Note: in these graphs, the yellow surface is the ground truth, the blue surface is the learned solution. The horizontal plane axes are inputs, the vertical axis is output.)
End of story? What if we zoom out…
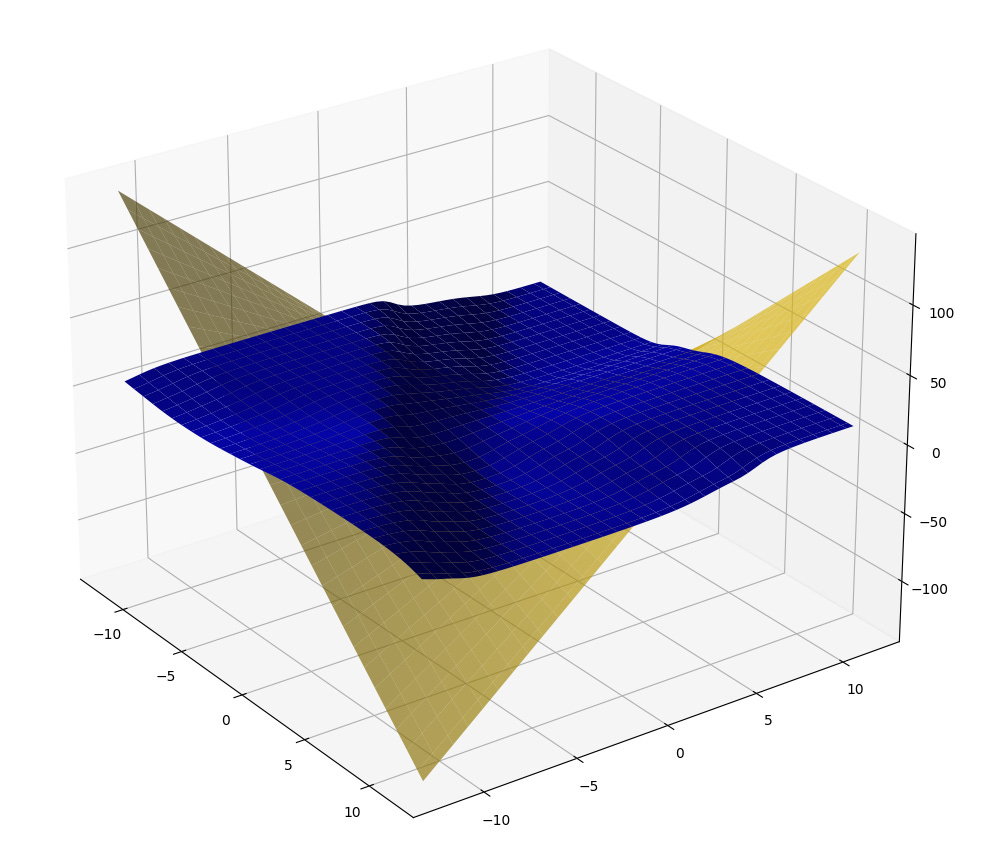
Oh. Well that did not go as planned. What happened?
Remember we just talked about approximating on an interval vs approximating globally? The network has only seen numbers in the range of [−3,3], so it learned to approximate multiplication on that interval. When we zoomed out to [−12,12], the network was tested on values it not only has never seen in training (that is true for the first image as well) but that were also out of the interval it was trained on (i.e. out of the training data distribution).
Basically, since the only data that the network was trained on was in the smaller interval, it had no reason to learn the function globally, and so it didn’t.
Ultimately, this issue can be (and is in practice) fought with an extremely wide/diverse training dataset, but it also illustrates a deeply interesting theoretical concern.
Data Flow Woes
We have now seen a network learn on an interval instead of globally twice. We have solutions to both of these cases (adding neurons for the first, increasing the dataset size/diversity for the second), but the question of why this happened in the first place still stands.
Did the multiplier network fail to generalize due to a fault in the experiment? The network design? The training procedure? Aren’t neural networks supposed to be infinitely versatile? Well, turns out, no conventional neural network can multiply.
You could still train a sufficiently large network to predict the value of a×ba \times ba×b over literally any finite interval, but there will always be a scale at which the approximation starts diverging.
To understand why, consider the way the variables are combined inside the network. Ultimately, we aim to combine aaa and bbb using multiplication. This must happen before the activation function, since it already operates on a single value and so cannot use both of the two inputs independently:
This leaves us with the linear combination part of the neuron which, no matter the weights of the neuron, will never exactly equal to a×b, since these values are combined by addition instead of multiplication:
What we have discovered here, is a very fundamental restriction on the expressive power of real-life neural networks. They cannot generally express multiplication.
Conclusion
Clearly, neural networks work in practice anyway. Maybe they don’t ever really have to multiply. But is it good enough to just learn functions on finite intervals? Especially if the size of these intervals is limited by the diversity of the training dataset? What edge cases are ML systems missing because they are unable to build complex extrapolation functions? What other functions are neural networks incapable of representing? What happens if one of these unrepresentable functions is important?
My personal intuition points towards two specific problems in which I think the limited expressiveness of neural networks has doomed them to fail. Both are based on proven practical phenomena and show the incredible ease with which neural networks can be broken:
The failure of networks to generally learn complex functions is the likely reason for out-of-distribution examples causing a 10% reduction in classification accuracy for all vision networks. (https://arxiv.org/abs/1902.10811)
The inability of networks to express fundamental functions is probably the reason why adversarial examples slip through the cracks so easily. (https://arxiv.org/abs/1705.07263, https://arxiv.org/abs/1608.04644)
If either of the above theories is true, the question becomes---how can we make neural networks represent more functions, more generally?
The Welch Labs video goes well with this!