
Vokenization: Multimodel Learning for Vision and Language

By Aryia Dattamajumdar
💡 Computer Vision meets Natural Language Processing
Vokenization is the bridge between visually supervised language models and their related images. In this blog post we explore the vokenization procedure and the inner works of the model and classification in two parts:
The first section of this post is beginner friendly, giving an overview of vokenization, NLP, and its ties to CV.
The second section, starting from the procedure, dives deep into the details of the model using weak supervision (more of a summary of the paper).
Introduction: Human Learning
How do humans learn langauges?
When humans distinguish words, they listen for temporal and frequency-based differences to determine what is being said. As toddlers, we pick up our first language by passively listening to our parents conversing. As we grow older, we learn to read, write, and talk with those around us. These four components (listening,reading,writing, and talking) help us interact with the world and understand our surroundings better. What if there were ways to bridge all of these domains to better understand language in computer models just like humans do?
❗️Spoiler alert: vokenization (keep reading to learn more)
Background in Computer Vision and NLP
Before we get into what vokenization is and how it works, let’s understand some key concepts and models in CV and NLP.
Breakthroughs in NLP allow machines to make sense of human languages, including tasks like text prediction, sentiment analysis, and speech recogition. Some popular pre-trained NLP models to know are GPT-3 by OpenAI, a deep learning text-generation framework, and BERT by Google, which produces embeddings representing each word in its provided sentence context.
Advances in computer vision and deep learning typically come from processing data in just one domain. For instance, the StyleGAN model, a type of GAN to adjust the style of an image at each convolution layer, is trained only on visual image data.

Figure 1: A Style-Based Generator Architecture for GANs (StyleGAN) created by NVIDIA researchers to generate artifical images, sometimes looking more authentic than the original images.
Similarly, GPT-3, believed to be the most powerful langauge model as of 2021,is trained only on text data. Despite this, there has been critisim towards BERT and GPT-3 lanaguge models as it’s difficult to learn the meaning of words from just pure text as an input. These self-supervised frameworks do not take into account information from the external visual world. If humans don’t learn by just reading, then why are existing language models solely based on text-only self-supervision?
To address this concern, there has been an increasing interest in the AI community to create vision-language representation learning, leveraging information from images to learn representations in language and vice-versa.
✨Vokenization✨
As of now, there’s a divide between visually-grounded langauge datasets and pure-language datasets. To bridge this gap, a new technique known as Vokenization has been developed. Along with other image-text neural network breathroughs in NLP like OpenAI’s DALL-E and CLIP, Vokenization is among the latest advancements in vision langauge multimodal modeling.
The name vokenization name stems from the combination of vision and tokens, forming vokens. A voken is an image that corresponds with a given language token and can be thought of as a visualization of a token.

Figure 2: A visualization of model-generated vokens in which the model classifies which visual voken corresponds with the language token.
Vokenization supervises language learning using visual information. It extrapolates multimodal alignments to language-only data through contextually mapping langauge tokens to vokens, a token’s related image. The image and token embeddings are retrieved from two respective deep neural networks and then the embeddings are aligned.
The novelty of the vokenization technique is that instead of just predicitng language tokens, image tokens are also predicted which is something that the vanilla BERT model cannot generate. Additionally, without requiring any change to the architecture, a pre-trained BERT model can be trained on Voken classification, giving performance gains on language only tasks like sentiment classification.

Figure 3: Combination of language tokens and token-related images. The language model is visually supervised with token-related images, known as vokens. The vokenization process generates a dataset of these contextual token image pairs.
What’s so significant about this?
On average the BERT model with the voken classification task, outperformed the BERT model without voken classification by about 3% average (that’s huge for an average!)
Vokenization Procedure
As an overview, the vokenization process is a contextual token-to-image matching model.
Current Challenges:
Grounded language prefers short and instructive descriptions, therefore having different distributions of sentence lengths and active words to other language types.
Most words from the natural language are not visually grounded (just 28% in the English Wikipedia).
We do this in two parts to address two challenges:
Challenge 1
We use our vokenization method in which we use relatively small datasets to train the vokenizer (vokenization processor). We then generate the vokens for a large language corpora like the English Wikipedia. The visually-supervised language model will then take in the input from the large datasets. This helps to bridge the gap between the different data sources which helps solve challenge 1.
Challenge 2
Some tokens that are not visually grounded can be mapped to related images while considering the context of the sentence. The contextual token-image matching model inside the vokenizer maps tokens to images by viewing context which allows us to generate vokens for the English Wikipedia.
Traditional language models predict language tokens. But with vokenization, instead of predicting just the language tokens, the image tokens are also predicted. The image tokens are classified from a pre-defined set of a fixed vocabulary/vokens for the images. Essentially, language models have a vocabulary set of different tokens which are mapped to an embedding table and then mapped into predictions of the other tokens.
Input: The model takes in both a sentence, which is made up of a sequence of tokens, and an image.
Output: Relevance score between the image and each token within its sentence context

Mapping examples of the language tokens into the images being classified. The voken BERT model classifies which voken corresponds to the language token. For instance, example 1 of the figure above, the speaking language token is matched to a phone in a hand.
Considering the image context, the model performs the cross attention over the entire sentence along the images to predict the voken. The figure above shows the language token “by” in both example 1 and example 2. However, in the context of the first sentence (example 1), the “by” image token is someone talking on a phone as opposed to in example 2 “by” is mapped to a bench in a park. This visual information helps the model further distinguish words in their contexts and leads to the improvement.
First we get a dataset of vokens, then we can train the actual vokenizer.
Warning: The next part goes into the model in depth. Let’s dive in the kinks of this procedure!
Tokens and Image Association:
Modeling
The vokenization process involves assigning each token wi in a sentence
with its relevant corresponding image, the voken v(wi ; s). However, instead of creating the image with generative models, instead they are retrived from a set of finite images containing image vocabulary.
Scoring Function:
Finite Image Set: x∈X
The scoring function parameterized by theta measures how close an image x is to a given token wi in context like a sentence s. We can model this scoring function as an inner product of the language feature representation fθ(wi; s) and the visual feature representation gθ(x) as the following:

The language encoder uses a pre-trained BERTBASE model to contextually embed each of the discrete tokens, {wi} into hidden output vectors {hi}. Next a multi-layer perceptron wmlpθ to the hidden output hi.
{hi}:
Language feature representation:
For the visual features, the visual encoder extracts e, the visual embedding, from a pre-trained ResNeXt. A multi-layer perceptron xmlpθ and L2 normalization layer are then applied as the following: e=ResNeXt(x).
Visual feature representation:
The optimal parameter of the scoring function is assumed to be θ∗. Thus the voken related to a token in the sentence is the image that maximizes their relevant score rθ∗.

This is similar to OpenAI’s recent work on CLIP which turns image classification into a text-similarity problem.

Above is some code from OpenAI’s CLIP. Note the similarity with the inner product between image and text embeddings.
Training: Weak Supervision
The vokenization model is trained with weak supervision which uses a suprvised learning loss functions but has noisy labels for data like programmatic labeling. Here to contruct the weakly supervised datasets, image captioning datasets with an image and sentence are used. These datasets are made of sentence-image pairs {(sk,xk)} where the sentence sk desribes the visual content in the image xk.
Positive token-image pair:
Negative token-image pair:
In the vokenization training every token in the caption is treated as a match with the image. We can randomly sample another image x′ as long as x′≠x. Then in the classification task, the hinge loss has a set margin M for applying the loss function. This is used to optimize weight θ so the score of the positive image-pair token is greater than the negative pair token by at least the margin.
Inference
To visualize the flow (figure 4), the tokenizer is run on the text corpus to produce a list of tokens. The tokens are then inputted into a language encoder while the visual encoder (ResNet model) runs every single image. And then, in order to find the image that’s the best match for a given token in a sentence, a scoring function is efficiently run on token image pairs, using some algorithm like Nearest Neighbor. This process successfully matches the image to token by retrieving the most similar encoding to the query encoding.
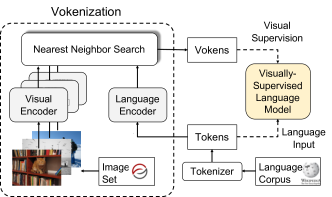
Figure 4: To implement the vokenization process, for the tokens in the language corpora, images are contextually retrieved using something like a Nearest Neighbors algorithm from the image set as vokens. These generated tokens are used from the visual supervision to the language model
Summary of Vokenization procedure
The model takes in both a sentence (composed of tokens) and an image as an input.
Assigns each token in the sentence to its corresponding relevant image
The sentence becomes a sequence of tokens in the vokenizer and this outputs a relevance score for the tokens and images within the context of the sentence.
-->
Results:
Table 1 (Pre-trained models with and without voken classification):

In the table above, the models are either pre-trained with a masked langauge model with an additional voken classification task (BERT6L/512H+Voken-cls, BERT12L/768H+Voken-cls) or just the masked language model (BERT6L/512H or BERT12L/768H).
The results of the vokenization procedure demonstrate promising gains of visually grounded supervision, showing better performance than language only tasks. For instance, on the SST-2 (sentiment classification) in the table above there is about a 3% improvement when adding the voken classification. This shows an improvement compared to purely self-supervised language models.
The visually grounded learning signal is super helpful and there are certainly more applications of vokenization😊
Applications:
The idea of combining vision and language learning will be popular in applications medical imaging - visual representation for autmoated medical image diagnosis in particular. This paper, Contrastive Learning of Medical Visual Representations from Paired Images and Text, for instance, explores radiograph images with short text descriptions in which semantic segmentation is time consuming. This vokenization technique could potentially bootstrap these representations and use the text information improved automated medical imaging.
There are lots of other possibilities for applications of vokens and other grounded language systems (to name a few below).
Vision-Touch for robotics
Vision-Audio
Language-Audio
As such advancements in NLP and CV continue,there certainly is a bright future ahead!
Sources:
Original Research Paper: Vokenization: Improving Language Understanding with Contextualized, Visual-Grounded Supervision
What Is Vokenization And Its Significance For NLP Applications
MIT Technology Review: This could lead to the next big breakthrough in common sense AI
