
MuZero: Checkmate For Software 1.0?


By Ashwin Reddy
Deep learning differs from mainstream software so starkly that Andrej Karpathy calls it Software 2.0. The name points to deep learning’s superiority in domains as complex as protein folding prediction. But I want to argue that deep learning, though it surpasses Software 1.0, still relies on classical techniques.
MuZero, an algorithm developed by Google DeepMind, serves as an excellent example of Software 2.0’s advancement. Consider its applications.
MuZero’s predecessor AlphaGo defeated champion Lee Sedol in a five-game Go match (Silver, 2016).
YouTube found promising results in compressing videos with MuZero.
Tesla’s self-driving cars navigate the real world using MuZero.
Yet MuZero and AlphaGo are at heart extensions of chess algorithms. Computing pioneers like Alan Turing and Claude Shannon worked on such chess algorithms, which remain fundamentally the same today. Broadly, they follow this procedure.
Consider all the moves you can make. For each move, determine where the game is likely to end. Concretely, build a game tree.
Choose the move ending in the highest score for the computer. To do this, use a heuristic, which assigns a score to each chess configuration. The heuristic might come from a human expert, or, as we’ll see later, learned from experience.

{kind=link}
DeepBlue defeated world chess champion Garry Kasparov with this approach in 1997. Because Go and chess are similar, you might think this algorithm could also play Go competently. But there are two problems.
Go uses a bigger board and allows for many more moves than chess. As a result, the game tree is bigger, and naive tree searches become too slow in practice.
Handcrafted heuristics haven’t been able to achieve human levels of Go performance.
In the ideal world of Software 2.0, we would design a single network that predicts optimal moves for a given Go board. The network learns a heuristic that runs in constant time, solving both problems. Collect or generate a dataset, train the model, and voila — problem solved.
If it were that simple, then we might expect MuZero to simply be a novel network architecture. Instead, DeepMind kept the tree structure. Rather than exhaustively searching the game tree, MuZero uses Monte Carlo Tree Search (MCTS), first used in Go programs in Brugman (1993), to focus on the most promising moves. Deep learning powers the heuristic, which in this case is a prediction function f.1
The value measures how good the state is, and the policy recommends the next action to take.
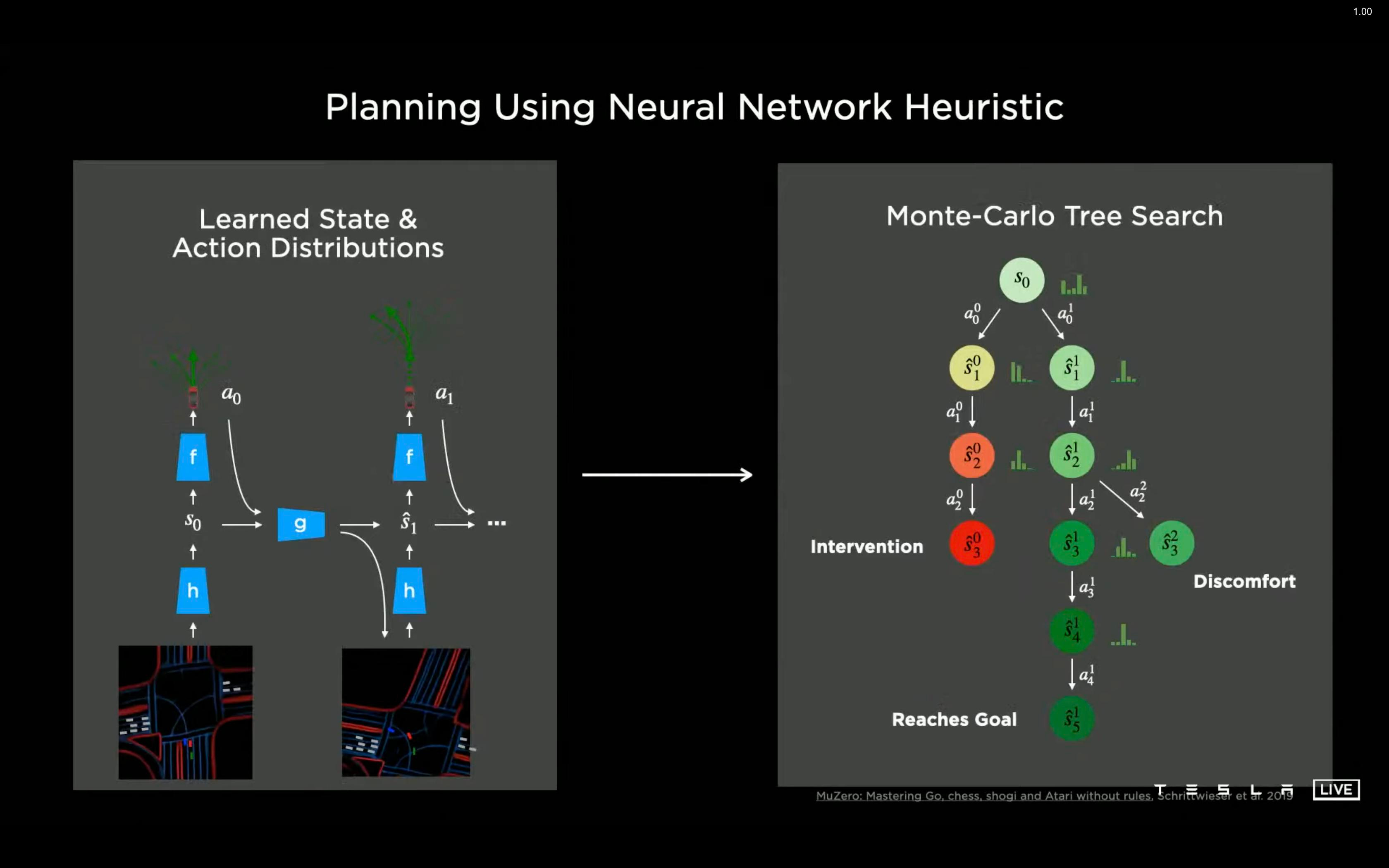
As the name Monte Carlo suggests, MCTS runs simulations to estimate how good a move is. For MuZero, the estimate is a visit count n(s,a), which counts how many times we have simulated action a in state s. To run a simulation, we do the following.
Use the value and policy from f(s) to pick the most promising move a.
Make move a and increment visit count n(s,a). Go to the next state.
Repeat steps (1) and (2) until we find a state we’ve never seen (i.e. with visit count 0).
To play a round of Go, we run one simulation and then pick the action with highest visit count, and repeat.2 We then update the policy to reflect the new visit counts. MCTS has more foresight than the policy because it sees more than a single step ahead. Schrittwieser et al. (2020) explain that “MCTS may therefore be viewed as a powerful policy improvement operator.”
Notice MCTS makes its decision from the visit counts; the policy and value only help to build the tree. If you want to encourage or discourage specific behaviors, you incorporate it into the tree, not the model. For example, Tesla prioritizes passenger comfort and penalizes the need for driver intervention through manual heuristics in the tree.
Software 2.0 promises neural networks that replace standard algorithmic approaches. But MuZero represents a continuation in the rich history of chess and Go algorithms, not a break from it. Because neural networks can’t handle the large state space or incorporate explicit factors, MuZero keeps the tree search approach, proving that a combination of deep learning and carefully chosen standard methods can dramatically outperform either one alone. In that regard, principled engineering and lucid algorithmic thinking still matter. For the time being, Software 2.0 will have to wait.
Citations
Schrittwieser, J., Antonoglou, I., Hubert, T. et al. Mastering Atari, Go, chess and shogi by planning with a learned model. Nature 588, 604–609 (2020). https://doi.org/10.1038/s41586-020-03051-4
Brügmann, B. (1993). Monte carlo go (Vol. 44). Syracuse, NY: Technical report, Physics Department, Syracuse University.
The functions h and g allow MuZero to capture the most relevant parts of the observation (the full chess or Go board or the car’s sensor information) and predict what will happen when different actions are taken.
This count is meant to correlate with how good a state is. A high visit count indicates high value with high confidence. We know it’s high value because we try to visit only promising states. Our confidence is high because we’ve seen it often.
 | A guest post by
|